해외AI/DS소식



메타 라마 2, 비용 효율성의 함정 작업 규모에 맞는 LLM 사용 중요 비용 절감 위한 최적화 방안 모색 [해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (GIAI R&D Korea)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
Read More











영국 AI 안전 서밋, 규제 방법에 대한 엇갈린 반응 미래의 위험보다 현재의 위험에 초점을 맞춰야 해 사람을 보호하기 위해 정부와 기업의 협력 필요 [해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (GIAI R&D Korea)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
Read More



바이든 대통령의 새로운 행정 명령으로 AI 안전 및 규제에 체계 부여 AI의 투명성과 안전을 강화하기 위한 연방 표준 설정에 초점 맞춰져 중요한 진전이지만 구체적인 시행 논의와 기술적 한계에 대한 우려 존재 [해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (GIAI R&D Korea)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
Read More

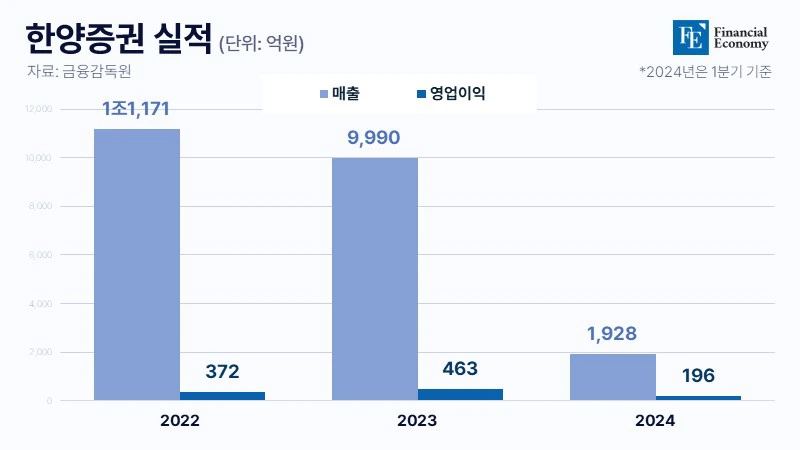
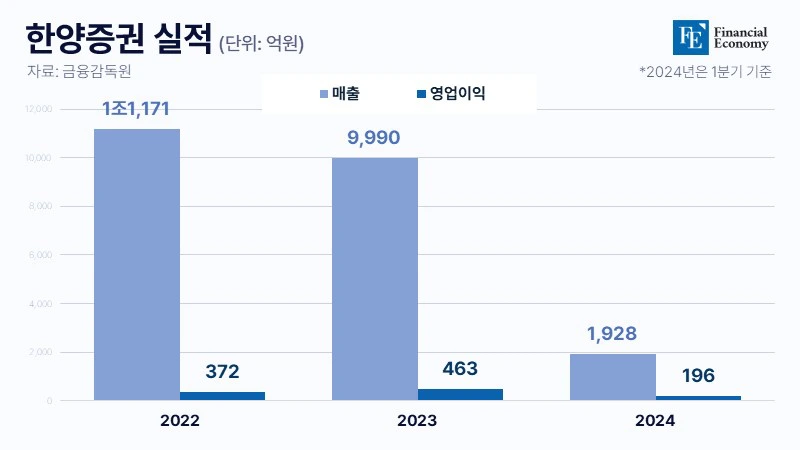
네이처지, "사람처럼 일반화할 수 있도록 돕는 새로운 훈련 방법 개발" 합성성을 위한 메타 러닝 접근법, 체계적인 학습 방법이 중요해 한계에도 불구하고 인간과 인공 지능의 학습 과정 이해 실마리 제공 [해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (GIAI R&D Korea)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
Read More

NFT로 자연스럽게 이어진 프로젝트 상업성과 작품성 모두 지킨 비결은 노골적인 소유 자극 아닌 비전의 설득력 [해외DS] AI와 인간의 예술 콜라보, 관객 참여᛫몰입 강화한다 (2)에서 이어집니다.
Read More
LA 필하모닉의 100년으로 장식한 디즈니 콘서트홀 데이터를 분류하고 맥락화 하는 데이터 유니버스 구축 ADA 기술로 '암기'에서 '응용'으로 진화한 AI [해외DS] AI와 인간의 예술 콜라보, 관객 참여᛫몰입 강화한다 (1)에서 이어집니다.
Read More
랜드마크를 캔버스 삼는 레픽 아나돌과 그의 스튜디오 인공지능과 함께 보고 듣고 상상해 '아카이브 드리밍' 통해 기억과 기억을 잇다 [해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (GIAI R&D Korea)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
Read More
