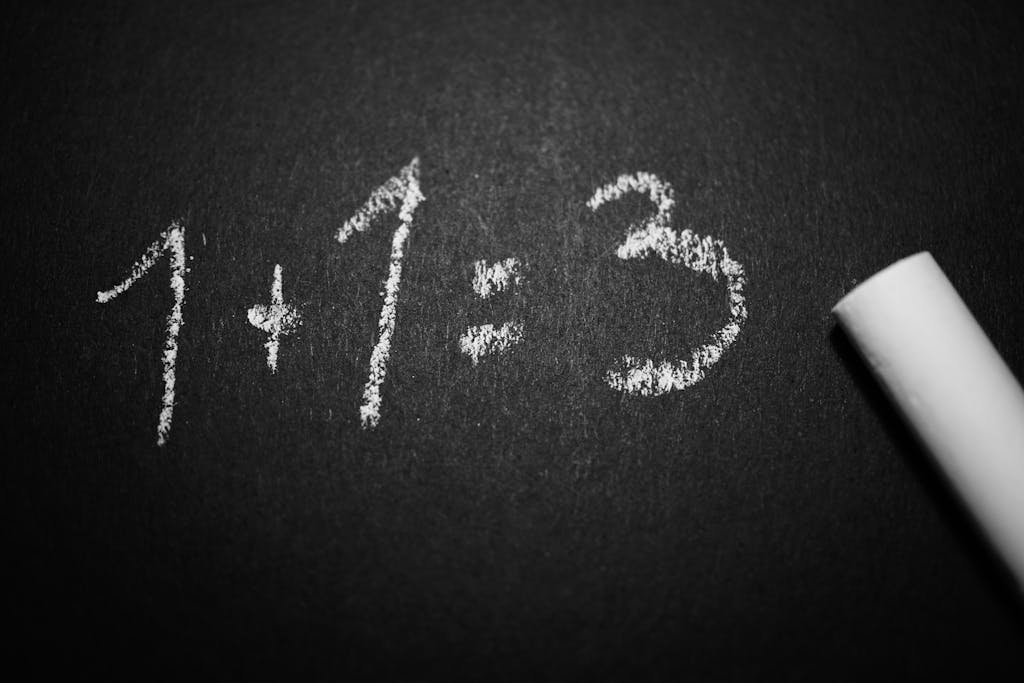Many people think machine learning is some sort of magic wand. If a scholar claims that a task is mathematically impossible, people start asking if machine learning can make an alternative. The truth is, as discussed from all pre-requisite courses, machine learning is nothing more than a computer version of statistics, which is a discipline that heavily relies on mathematics.
Read More
WSJ, 미국 테크 기업들 AI 인재 채용 줄여, A급 인재만 채용단순 지식 뿐만 아니라 응용력, 협업 능력까지, 팔방미인 따져가며 채용국내도 늦었지만 개발자와 AI전문가 구분하기 시작해 26일 월스트리트저널(WSJ)에 따르면, 미국 테크 기업들이 AI에 막대한 투자를 이어가고 있는 와중에도 예전처럼 AI개발자 채용을 대규모로 진행하지는 않는다고 한다. 일부 A급 인재를 제외하면 해고 압박이 심하고, 재교육 부담이 가중되고 있다는 것이다. 지난 2018년부터 줄기차게 주장했던대로, 진작부터 이렇게 됐었어야 했는데, 투자금과 정부 지원금이 넘쳐났던 덕분에 시장의 교정 작업이 좀 늦어졌다고 본다. IT업계의 개발자라는 직군과 데이터 과학자, 혹은 AI 연구자(Researcher)로 불리는 직군 사이에는 아이돌과 판소리 급의 격차가 있다는 것이 조금씩 시장에 받아들여지는 모습이다.
Read More












Generative models are simply repeatedly updated model. Unlike discriminative models that we have learned from all previous lectures, such as linear/non-linear regressions, SVM, tree models, and Neural Networks, Generative models are closely related to Bayesian type updates. RBM (Restricted Boltzmann Machine) is one of the example models that we learned in this class. RNN, depending on the weight assignment for memory, can qualify generativeness.
Read More
Recurrent Neural Network (RNN) is a neural network model that uses repeated processes with certain conditions. The conditions are often termed as 'memory', and depending on the validity and reliance of the memory, there can be infinitely different variations of RNN. However, whatever the underlying data structure it can fit, the RNN model is simply an non-linear & multivariable extension of Kalman filter.
Read More
Constructing an Autoencoder model looks like an art, if not computationally heavy work. A lot of non-trained data engineers rely on coding libraries and a graphics card (that supports 'AI' computation), and hoping the computer to find an ideal Neural Network. As discussed in previous section, the process is highly exposed to overfitting, local maxima, and humongous computational cost. There must be more elegant, more reasonable, and more scientific way to do so.
Read More
Bayesian estimation tactics can be used to replace arbitrary construction of deep learning model's hidden layer. In one way, it is to replicate Factor Analysis in every layer construction, but now that one layer's value change affects the other layers. This process goes from one layer to all layers. What makes this job more demanding is that we are still unsure the next stage's number of nodes (or hidden factors) are right, precisely as we are unsure about the feeding layer's node numbers. In fact, everything here is unsure, and reliant to each other.
Read More
As was discussed in [COM502] Machine Learning, the introduction to deep learning begins with history of computational methods as early as 1943 where the concept of Neural Network first emerged. From the departure of regression to graph models, major building blocks of neural network, such as perceptron, XOR problem, multi-layering, SVM, and pretraining, are briefly discussed.
Read More
Feed forward and back propagation have significant advantage in terms of speed of calculation and error correction, but it does not mean that we can eliminate the errors. In fact the error enlarges if the fed data leads the model to out of convergence path. The more layers there are, the more computational resources required, and the more prone to error mis-correction due to the structure of serial correction stages in every layer.
Read More
본 문서는 GIAI 산하에서 운영되는 스위스AI대학(Swiss Institute of Artificial Intelligence, SIAI)의 강의노트 중 일부를 한국어로 번역한 것입니다. 영어 원문 및 전체 버전은 아래의 링크를 통해 확인하시기 바랍니다. 학부/예비석사 과정 정규 석사 과정 아래에 번역된 노트는 학부/예비석사 과정, 혹은 AI MBA 과정에서 발췌 했습니다. 학업에 바쁜 와중에도 번역을 맡아주신 김광재(MBA AI/BigData, 2023), 전웅(MBA AI/BigData, 2023) 학생들께 감사를 표합니다.
Read More

AI 열풍에 휩쓸린 사람들은 대부분 심각한 오해에 빠져 있어현재 AI/데이터 과학은 여전히 통계적 방법론에 국한돼과장된 선전은 무지와 오해를 키울 뿐 AI/데이터 과학 교수로 일하다 보면, 이따금 AI 과대광고에 휩쓸린 사람들로부터 이메일을 받곤 한다. 그들이 '최신 AI'라고 부르는 것으로 내가 평소 비관적으로 생각해 온 문제들을 모두 해결할 수 있다고 주장하는 내용들이다. 보통 이런 사람들은 '최신 AI' 프로그램이 스스로 학습하여 인간의 지능 수준을 완전히 뛰어넘은 '인공 일반 지능'(AGI)에 근접했다고 여기는 열렬한 AI 신봉자들이다.
Read More
과거 정신 감정, 지능 검사 등에 국한됐던 직원 선별에 조직 문화 적응 역량도 추가되는 추세미국은 직원들의 SNS 활동을 추척한 조용한 퇴사 지표 개발 필요성 제기되자 논란 되기도기업들이 고용 계약 대신 프리랜서 계약을 들이미는 경우도 늘어 가깝게 지내는 국내 주요 스타트업 핵심 멤버들을 만나면, 어느 중소기업이나 마찬가지듯이 직원을 못 뽑아서 힘들다는 이야기들을 한다. 나 역시 마음에 드는 직원을 뽑기가 쉽지 않기 때문에 어떻게 선별 작업을 '인공지능(AI)'을 써서 자동화하면 좀 더 효율적으로 채용 절차를 진행할 수 있을까 고민이 많은데, 지난 1년 남짓은 직무에 직접 관련된 시험을 치는 것으로 절차를 단순화 해 왔다.
Read More
People following AI hype are mostly completely misinformedAI/Data Science is still limited to statistical methodsHype can only attract ignorance As a professor of AI/Data Science, I from time to time receive emails from a bunch of hyped followers claiming what they call 'recent AI' can solve things that I have been pessimistic. They usually think 'recent AI' is close to 'Artificial General Intelligence', which means the program learns by itself and it is beyond human intelligence level.
Read More