[해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (MDSA R&D)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
사진=Scientific American
뫼비우스의 띠는 흥미로운 수학적 대상이다. 안과 밖의 구별이 없는 이 단면 표면을 만들려면 종이 조각을 가져다가 한 번 비틀고 끝을 테이프로 붙이면 된다. 어린아이들도 할 수 있을 정도로 간단하게 뫼비우스 띠를 만들 수 있지만, 도형의 성질은 수학자들의 지속적인 관심을 끌 만큼 복잡하다.
뫼비우스의 띠를 만들 수 있는 최소 길이는?
1858년 뫼비우스 띠를 발견한 공로로 두 명의 독일 수학자 아우구스트 페르디난트 뫼비우스(August Ferdinand Möbius)와 요한 베네딕트 리스팅(Johann Benedict Listing)를 언급하지만 수학의 거장 칼 프리드리히 가우스(Carl Friedrich Gauss)도 같은 시기에 이 도형을 알고 있었다는 증거가 있다고 스토니브룩 대학교의 수학자인 모이라 차스(Moira Chas)가 말했다. 뫼비우스 띠에 대해 누가 처음 생각했는지에 관계없이, 최근까지 연구자들은 겉보기에 쉬운 질문 하나에 당황했다: "뫼비우스 띠를 만드는 데 필요한 가장 짧은 종이 길이는 무엇일까?" 브라운 대학교의 수학자 리처드 에반 슈워츠(Richard Evan Schwartz)는 Embedded 형태, 즉 스스로 관통하거나 교차하지 않는 매끄러운 뫼비우스 띠의 경우 이 문제가 해결되지 않았었다고 설명했다. Immersed 형태는 종이 길이가 짧아도 겹진 상태로 뫼비우스의 띠를 만들 수 있지만, Embedded 띠는 종이가 서로 겹치는 것을 허용하지 않기 때문에 종이 길이가 너무 짧으면 뫼비우스의 띠를 만들 수 없게 된다. 바로 이지점이 Embedded 띠가 가질 수 있는 최소 길이에 대한 궁금증을 갖게 되는 동기다.
1977년 수학자 찰스 시드니 위버(Charles Sidney Weaver)와 벤자민 리글러 할펀(Benjamin Rigler Halpern)은 최소 길이에 대한 이 질문을 제기하면서 "뫼비우스 띠가 자기 교차점을 갖도록 허용하면 문제가 쉬워진다"고 말했다고 캘리포니아 대학교 데이비스 캠퍼스의 수학자 드미트리 푹스(Dmitry Fuchs)가 전했다. 남은 질문은 "비공식적으로 말하자면 자기 교차점을 피하고자 얼마나 많은 공간이 필요한지 결정하는 것"이라고 푹스는 덧붙였다. 할펀과 위버는 최소 크기를 가정했지만, 할펀-위버 추측이라고 불리는 이 아이디어를 증명할 수는 없었다.
남다른 슈워츠의 증명 방식
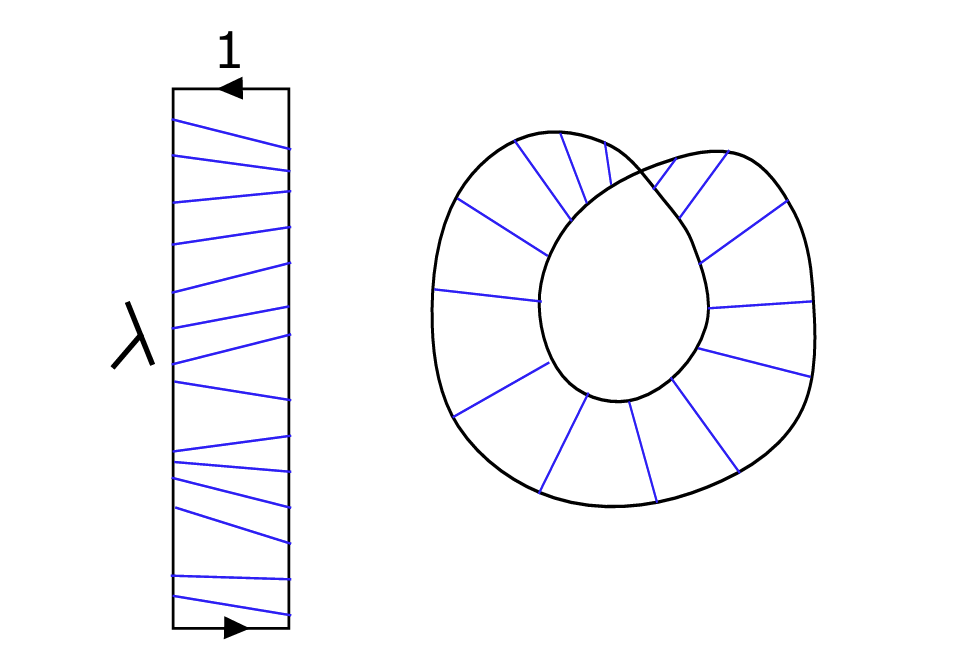
슈워츠는 약 4년 전 펜실베이니아 주립대의 수학자 세르게이 타바치니코프(Sergei Tabachnikov)를 통해 이 문제를 처음 알게 됐고, 타바치니코프와 푹스가 쓴 책에서 이 주제에 관한 챕터을 읽었다. "그 챕터를 읽고 완전히 매료되었습니다"라고 그는 회상했다. 그의 왕성한 호기심은 문제에 대한 해결책으로 결실을 보았다. 슈워츠는 8월 24일 arXiv.org에 게재된 논문에서 할펜-위버의 가설을 증명했다. 그는 종이로 만든 Embedded 형 뫼비우스 띠는 가로세로비가 √3(약 1.73)보다 큰 경우에만 구성할 수 있음을 보여주었다. 예를 들어 띠의 너비가 1cm인 경우 길이는 √3cm보다 길어야 한다.
이 난제를 해결하려면 창의력이 필요했다. 일반적인 접근 방식을 사용하면 "공식을 사용하여 자기 교차하는 표면과 자기 교차하지 않는 표면을 구별하기가 항상 어렵습니다"라고 푹스가 강조했다. "이 어려움을 극복하려면 슈워츠의 기하학적 시각이 필요합니다. 하지만 이런 시도는 매우 드뭅니다!"
독일 괴팅겐 대학의 수학자인 맥스 와데츠키(Max Wardetzky)는 "슈워츠는 큰 문제를 작은 조각들로 분해했으며, 각 조각은 기본적인 기하학만 있으면 풀 수 있는 쉬운 문제로 변했습니다"라고 감탄했다. "이러한 증명 방식은 가장 순수한 형태의 우아함과 아름다움을 구현해 냅니다."
그러나 슈워츠는 증명에 성공하기 전까지 몇 년에 걸쳐 다른 전략을 시도했다가 실패했었다. 그러다 최근 그는 2021년 논문에서 사용했던 접근 방식이 효과가 있었어야 한다는 생각이 들어 이 문제를 다시 검토하기로 했다. 그의 직감이 맞았다. 문제 조사를 재개했을 때 그는 이전 논문에서 'T-패턴'과 관련된 중간 결과인 한 부명제(lemma)에 실수가 있음을 발견했다. 슈워츠는 이 오류를 수정함으로써 할펀-위버의 가설을 빠르고 쉽게 증명했다. 그 실수만 아니었다면 3년 전에 이 문제를 해결했을 것이라고 슈워츠는 말했다.
"평행사변형이 아니었어?"
할펀-위버 추측에 대한 슈워츠의 해결책에서 T-패턴 부명제는 굉장히 중요한 구성 요소였다. "뫼비우스 띠는 '선직면'(ruled surface)이라고 불리는 직선들이 있습니다"라고 그는 설명하기 시작했다. 다른 종이 물체도 이 속성을 공유하고, "한 공간에 종이가 있을 때 그것이 복잡한 위치에 있더라도 모든 지점에는 직선이 통과합니다."라고 슈워츠는 말했다. 이 직선이 뫼비우스 띠를 가로질러 양쪽 끝에서 경계에 부딪히도록 그리는 것을 상상할 수 있다.
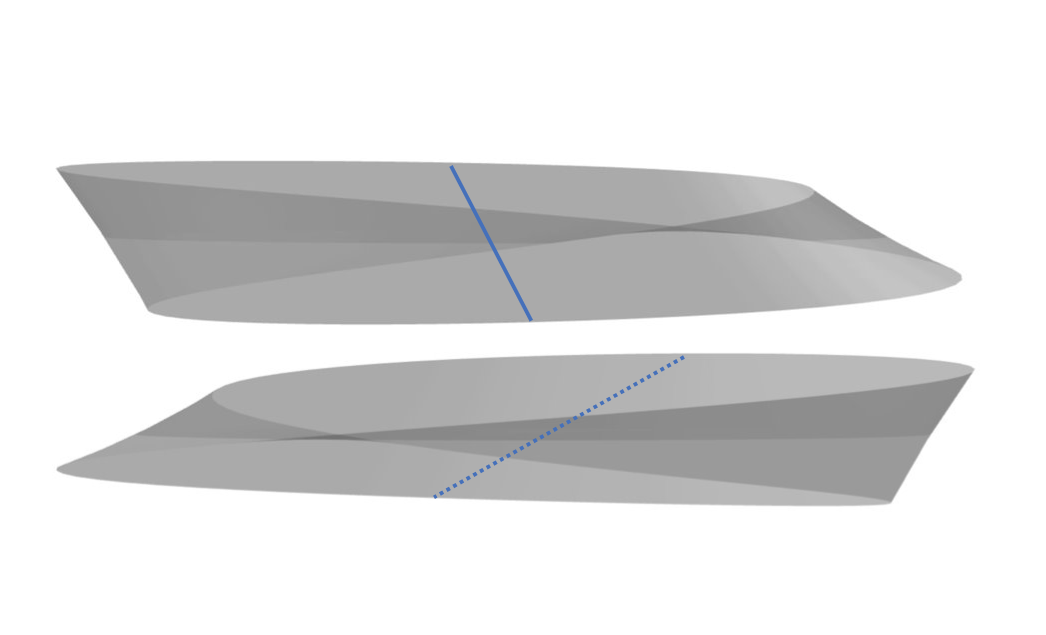
슈워츠는 이전 연구에서 서로 수직이면서 같은 평면에 있는 두 개의 직선이 모든 뫼비우스 띠에 T 패턴을 형성하는 것을 확인했다. 아래 그림에서 진한 파란색 선이 있는 뫼비우스의 띠가 지구본처럼 오른쪽으로 회전하고 있다고 상상해 보자. 진한 파란색 선이 반대편에 도달했을 때는 뫼비우스의 성질로 인해 파란색 점선처럼 뒤집혀 있을 것이다. 두 직선을 겹쳐서 본다면 수직을 이루는 걸 확인할 수 있다. 이 한 쌍의 직선을 T 패턴이라고 부르고 다른 임의의 직선에 대해서도 동일한 T 패턴을 발견할 수 있다. T 패턴의 존재가 수수께끼를 푸는 첫 번째 단추였다.
T 패턴의 이해를 돕기 위한 참고용 자료(뫼비우스 띠의 정확한 묘사가 아니다)
다음 단계는 뫼비우스 띠를 파란색 선을 따라 비스듬한 방향으로 잘라내고 잘린 모양을 고려해서 최소 길이를 찾아내는 최적화 작업이다. 이 단계에서 슈워츠는 2021년 논문에서 잘린 도형이 평행사변형이라고 잘못 결론을 내려 틀린 결괏값을 얻었다.
올여름, 슈워츠는 다른 방법을 시도하기로 하고 종이 뫼비우스 띠를 납작하게 평면화해서 실험하기 시작했다. 그는 "뫼비우스 띠를 평면으로 누를 수 있다는 것을 보여줄 수 있다면 평면 물체만 생각하면 되는 더 쉬운 문제로 단순화할 수 있을 것"이라고 생각했다.
실험 도중 뫼비우스 띠를 자르던 슈워츠는 깜짝 놀랐다. "맙소사, 이건 평행사변형이 아니구나! 사다리꼴이었네." 실수를 발견한 슈워츠는 처음에는 화가 났지만("저는 실수하는 것이 싫어요."), 사다리꼴 모형에 맞게 길이를 다시 계산했다. "수정된 계산을 통해 추측했던 숫자가 나왔습니다"라고 그는 전했다. "깜짝 놀랐죠.... 3일 동안 거의 잠을 자지 않고 이걸 작성하는 데만 시간을 보냈습니다"라고 당시 격양된 상황을 설명했다.
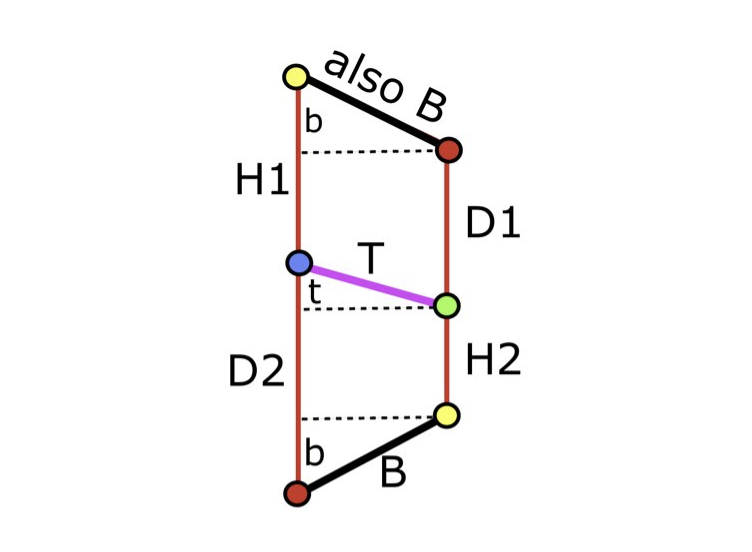
파란색 선을 따라서 비스듬히 뫼비우스의 띠를 자르면 사다리꼴 모양이 나온다/사진=The Optimal Paper Moebius Band (Informally)
위의 그림에서 같은 색상의 노드끼리 맞춰서(빨강-빨강, 노랑-노랑) 잘린 파란색 선(B)을 꼬아서 다시 붙이면 파란색 선이 분홍색 T 선과 수직임을 눈으로 다시 한번 확인 할 수 있고, 아래와 똑같은 평면상의 종이접기 문제로 단순화할 수 있음을 직관적으로 느낄 수 있을 것이다.
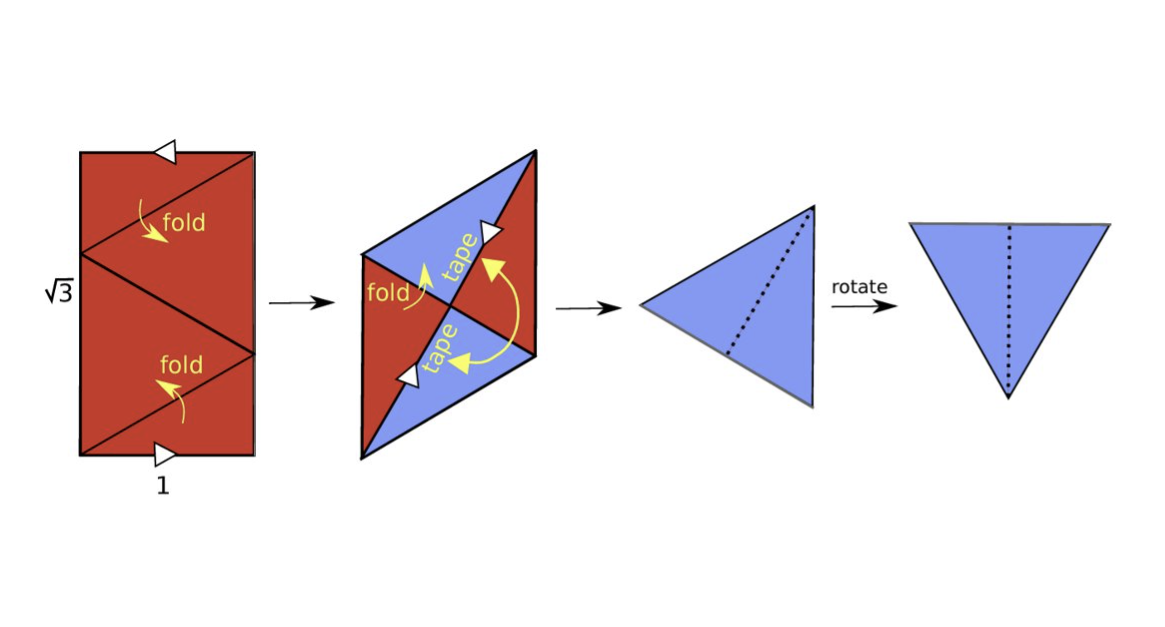
실습하면서 T 패턴을 발견한 슈워츠의 기쁨을 함께 누려보자. 뫼비우스의 띠를 하나 만들어서 비스듬한 파란색 직선을 먼저 그린다. 띠를 반대편으로 돌리면서 뒤집히는 모양도 확인해 보고 원래 위치의 선과 수직을 이루는 것도 상상한다(원래 위치의 직선 모양을 기억하고 있어야 한다). 그 후 선을 따라 자르면 사다리꼴이 나온다. 잘린 선들을 원래 위치로 다시 붙이는 과정에서 반대편에 뒤집힌 선과의 수직을 이루는 것을 더 확실하게 볼 수 있다. 아래 색종이 접기도 직접 해보면 위와 똑같은 행위임을 느낄 수 있다. 결국 뫼비우스의 띠에서 모든 임의의 파란색 선(비스듬한 직선)에 대해 똑같이 T 패턴을 찾을 수 있기 때문에 아래의 간단한 종이 접기 문제로 간소화할 수 있다. 슈워츠의 비범함이 여기서 나타난다.
마침내 반세기가 넘은 질문에 대한 답이 나왔다. 타바치니코프는 "오랫동안 풀리지 않았던 문제를 해결하려면 용기가 필요하다"라고 말했다. "이것은 리처드 슈워츠의 수학에 대한 접근 방식의 특징입니다. 그는 쉬워 보이지만 어렵다고 알려진 문제를 공격하는 것을 좋아합니다. 그리고 그는 이전 연구자들이 미처 발견하지 못한 새로운 측면을 발견합니다."
"저는 수학을 인류의 공동 작업이라고 생각합니다"라고 차스는 운을 뗐다. "뫼비우스, 리스팅, 가우스에게 '당신이 시작했고, 이제 이것 좀 보세요...'라고 말할 수 있으면 좋겠어요. 아마도 수학의 하늘 어딘가에서 그들은 우리를 바라보며 '오, 이런!'이라고 생각할 것입니다."
수학자들은 뫼비우스 띠를 얼마나 길게 만들 수 있는지에 대한 제한이 없다는 것을 이미 알고 있다(물리적으로 뫼비우스 띠를 만드는 것은 언젠가는 번거로워지겠지만 말이다). 하지만 한 장이 아닌 세 장이 꼬인 뫼비우스 띠를 만드는 데 사용할 때 종이의 길이가 얼마나 짧을 수 있는지는 아무도 모른다고 슈워츠는 지적합니다. 더 일반적으로는 "홀수 개의 꼬임을 만드는 뫼비우스 띠의 최적 크기에 관해 물어볼 수 있습니다."라고 타바치니코프는 말했다. "가까운 시일 내에 누군가가 이 문제를 해결할 것으로 기대합니다."
Möbius strips are curious mathematical objects. To construct one of these single-sided surfaces, take a strip of paper, twist it once and then tape the ends together. Making one of these beauties is so simple that even young children can do it, yet the shapes’ properties are complex enough to capture mathematicians’ enduring interest.
The 1858 discovery of Möbius bands is credited to two German mathematicians—August Ferdinand Möbius and Johann Benedict Listing—though evidence suggests that mathematical giant Carl Friedrich Gauss was also aware of the shapes at this time, says Moira Chas, a mathematician at Stony Brook University. Regardless of who first thought about them, until recently, researchers were stumped by one seemingly easy question about Möbius bands: What is the shortest strip of paper needed to make one? Specifically, this problem was unsolved for smooth Möbius strips that are “embedded” instead of “immersed,” meaning they “don't interpenetrate themselves,” or self-intersect, says Richard Evan Schwartz, a mathematician at Brown University. Imagine that “the Möbius strip was actually a hologram, a kind of ghostly graphical projection into three-dimensional space,” Schwartz says. For an immersed Möbius band, “several sheets of the thing could overlap with each other, sort of like a ghost walking through a wall,” but for an embedded band, “there are no overlaps like this.”
In 1977 mathematicians Charles Sidney Weaver and Benjamin Rigler Halpern posed this question about the minimum size and noted that “their problem becomes easy if you allow the Möbius band you are making to have self-intersections,” says Dmitry Fuchs, a mathematician at the University of California, Davis. The remaining question, he adds, “was to determine, informally speaking, how much room you need to avoid self-intersections.” Halpern and Weaver proposed a minimum size, but they couldn’t prove this idea, called the Halpern-Weaver conjecture.
Schwartz first learned about the problem about four years ago, when Sergei Tabachnikov, a mathematician at Pennsylvania State University, mentioned it to him, and Schwartz read a chapter on the subject in a book Tabachnikov and Fuchs had written. “I read the chapter, and I was hooked,” he says. Now his interest has paid off with a solution to the problem at last. In a preprint paper posted on arXiv.org on August 24, Schwartz proved the Halpern-Weaver conjecture. He showed that embedded Möbius strips made out of paper can only be constructed with an aspect ratio greater than √3, which is about 1.73. For instance, if the strip is one centimeter wide, it must be longer than √3 cm.
Solving the quandary required mathematical creativity. When one uses a standard approach to this type of problem, “it is always difficult to distinguish, by means of formulas, between self-intersecting and non-self-intersecting surfaces,” Fuchs says. “To overcome this difficulty, you need to have [Schwartz’s] geometric vision. But it is so rare!”
In Schwartz’s proof, “Rich managed to dissect the problem into manageable pieces, each of which essentially necessitated only basic geometry to be solved,” says Max Wardetzky, a mathematician at the University of Göttingen in Germany. “This approach to proofs embodies one of the purest forms of elegance and beauty.”
Before arriving at the successful strategy, however, Schwartz tried other tactics on and off again over a few years. He recently decided to revisit the problem because of a nagging sensation that the approach he had used in a 2021 paper should have worked.
In a way, his gut feeling was correct. When he resumed investigating the problem, he noticed a mistake in a “lemma”—an intermediate result—involving a “T-pattern” in his previous paper. By correcting the error, Schwartz quickly and easily proved the Halpern-Weaver conjecture. If not for that mistake, “I would have solved this thing three years ago!” Schwartz says.
In Schwartz’s solution to the Halpern-Weaver conjecture, the T-pattern lemma is a critical component. The lemma begins with one basic idea: “Möbius bands, they have these straight lines on them. They’re [what are] called ‘ruled surfaces,’” he says. (Other paper objects share this property. “Whenever you have paper in space, even if it’s in some complicated position, still, at every point, there’s a straight line through it,” Schwartz notes.) You can imagine drawing these straight lines so that they cut across the Möbius band and hit the boundary at either end.
In his earlier work, Schwartz identified two straight lines that are perpendicular to each other and also in the same plane, forming a T-pattern on every Möbius strip. “It is not at all obvious that these things exist,” Schwartz says. Showing that they do was the first part of proving the lemma, however.
The next step was to set up and solve an optimization problem that entailed slicing open a Möbius band at an angle (rather than perpendicular to the boundary) along a line segment that stretched across the width of the band and considering the resulting shape. For this step, in Schwartz’s 2021 paper, he incorrectly concluded that this shape was a parallelogram. It’s actually a trapezoid.
This summer, Schwartz decided to try a different tactic. He started experimenting with squishing paper Möbius bands flat. He thought, “Maybe if I can show that you can press them into the plane, I can simplify it to an easier problem where you’re just thinking of planar objects.”
During those experiments, Schwartz cut open a Möbius band and realized, “Oh, my God, it’s not the parallelogram. It’s a trapezoid.” Discovering his mistake, Schwartz was first annoyed (“I hate making mistakes,” he says) but then driven to use the new information to rerun other calculations. “The corrected calculation gave me the number that was the conjecture,” he says. “I was gobsmacked.... I spent, like, the next three days hardly sleeping, just writing this thing up.”
Finally, the 50-year-old question was answered. “It takes courage to try to solve a problem that remained open for a long time,” Tabachnikov says. “It is characteristic of Richard Schwartz’s approach to mathematics: He likes attacking problems that are relatively easy to state and that are known to be hard. And typically he sees new aspects of these problems that the previous researchers didn’t notice.”
“I see math as a joint work of humanity,” Chas says. “I wish we could tell Möbius, Listing and Gauss, ‘You started, and now look at this....’ Maybe in some mathematical sky, they are there, looking at us and thinking, ‘Oh, gosh!’”
As for related questions, mathematicians already know that there isn’t a limit on how long embedded Möbius strips can be (although physically constructing them would become cumbersome at some point). No one, however, knows how short a strip of paper can be if it’s going to be used to make a Möbius band with three twists in it instead of one, Schwartz notes. More generally, “one can ask about the optimal sizes of Möbius bands that make an odd number of twists,” Tabachnikov says. “I expect someone to solve this more general problem in the near future.”
[email protected]
세상은 다면적입니다. 내공이 쌓인다는 것은 다면성을 두루 볼 수 있다는 뜻이라고 생각하고, 하루하루 내공을 쌓고 있습니다. 쌓아놓은 내공을 여러분과 공유하겠습니다.
입력
수정
[해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (MDSA R&D)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
사진=Scientific American
주관적 경험이란 무엇이며, 누가 그것을 가졌는지, 그리고 그것이 우리 주변의 물리적 세계와 어떻게 관련되어 있는지에 대한 질문은 오랜 시간 동안 철학자들의 관심을 끌어왔다. 그러나 정량화할 수 있고 경험적으로 테스트할 수 있는 의식 이론의 등장은 수십 년밖에 안 됐다. 이러한 이론의 대부분은 의식이 생겨나는 뇌의 신경 활동에 초점을 맞추고 있다.
이러한 의식의 흔적을 추적하는 데 있어 그 진전이 매우 분명하게 드러나는 행사가 열렸었다. 6월 뉴욕대학에서 열린 공개 행사에서 오늘날 의식의 두 가지 지배적인 이론인 '정보 통합 이론'(Integrated Information Theory, 이하 IIT)과 '전역 작업 공간 이론'(Global Neuronal Workspace Theory, 이하 GNWT)의 지지자들 간의 '적대적 협력'을 통해 선의의 경쟁이 펼쳐졌고, 관점의 다양성은 어지러울 정도였다. 그리고 이 행사의 하이라이트는 뉴욕대학교의 철학자 데이비드 차머스(David Chalmers)와 필자 사이의 25년 전 내기의 결말이었다.
필자는 차머스에게 고급 와인 한 상자를 걸고 2023년 6월까지 의식의 신경 상관관계라고 불리는 이 신경 활동이 명확하게 발견되고 설명할 수 있게 될 것이라고 내기를 걸었다. 하지만 IIT와 GNWT 간의 대결은 아직도 해결되지 않은 채로 남아있다. 왜냐하면 시각적 경험과 얼굴이나 물체를 보는 주관적 감각을 담당하는 뇌의 영역에 관한 주장이 상충하기 때문이다. 그래서 필자는 내기에서 졌고 와인을 찰머스에게 선물했다.
이 두 가지 지배적인 이론은 사람이나 동물의 신경 활동과 의식의 관계를 설명하기 위해 개발되었다. 그러나 주관적 경험에 대해 근본적으로 다른 가정을 하고 있으며, 인공 지능의 의식과 관련하여 상반된 결론에 도달한다. 따라서 추후 해당 이론의 실증적 검증 결과는 기계가 지성을 가질 수 있는가에 대한 질문의 답과 매우 밀접한 관계를 맺게될 것이다.
챗봇의 지능
본론에 앞서 의식이 있는 기계와 지능적인 행동만 보이는 기계의 차이점을 알아보자. 컴퓨터 엔지니어들이 추구하는 성배는 호모 사피엔스가 아프리카를 벗어나 지구 전체로 뻗어나갈 수 있게 해준 고도로 유연한 지능을 기계에 부여하는 것이다. 이를 '인공 일반 지능'(이하 AGI)이라고 한다. 많은 사람이 AGI는 먼 목표라고 주장했으나 지난 한 해 동안 인공 지능의 놀라운 발전은 전문가를 포함한 전 세계를 놀라게 했다. 챗봇이라고 불리는 유창한 대화형 애플리케이션의 등장은 공상과학 애호가와 실리콘 밸리 괴짜들 사이의 난해한 주제에서 우리 삶의 방식과 인류에 대한 실존적 위험에 대한 대중의 일상 논쟁으로 확산했다.
이러한 챗봇은 대규모 언어 모델(이하 LLM)에 의해 구동되며, 가장 유명한 것은 OpenAI에서 만든 GPT라는 챗봇이다. OpenAI의 가장 최근 모델인 GPT-4의 유동성, 문해력 및 역량을 고려할 때, 이 챗봇이 인격을 가지고 있다고 믿기 쉽다. 심지어 '환각'으로 알려진 결함조차도 인격을 가진 결과라고 믿는 경우가 생겼다.
GPT-4와 그 경쟁자, 즉 Google의 LaMDA와 Bard, Meta의 LLaMA 등은 웹 크롤러를 통해 공개적으로 액세스할 수 있는 디지털 라이브러리와 수십억 개의 웹 페이지를 학습했다. LLM의 놀라운 점은 자동으로 단어 한두 개를 가리고 누락된 표현을 예측하는 방식으로 스스로 학습한다는 점이다. 이 과정은 누구의 개입도 없이 수십억 번을 반복해서 수행된다. 인류의 디지털 글을 수집하여 학습을 마치면 한 사용자가 모델이 한 번도 본 적이 없는 문장을 입력한다. 그러면 가장 가능성이 높은 단어와 그다음 단어를 예측하는 방식으로 응답한다. 이 간단한 원리로 영어, 독일어, 중국어, 힌디어, 한국어를 비롯해 다양한 프로그래밍 언어를 포함한 더 많은 언어에서 놀라운 결과를 얻었다.
1950년 영국의 논리학자 앨런 튜링이 '계산 기계와 지능'이라는 제목으로 쓴 에세이는 "기계가 생각할 수 있는가"라는 주제를 피했다. 대신 튜링은 '모방 게임'을 제안했다. 인간과 기계의 정체가 숨겨져 있을 때 관찰자가 인간과 기계가 입력한 결과물을 객관적으로 구별할 수 있는지를 묻는 실험이다. 오늘날 이 실험은 튜링 테스트로 알려져 있으며, 챗봇은 이 테스트를 가볍게 통과했다. 튜링의 전략은 수십 년에 걸친 끊임없는 발전을 통해 GPT로 이어졌지만 근본적인 질문은 해소하지 못했다.
이 논쟁에는 인공 지능이 인공 의식과 동일하며, 똑똑하다는 것은 의식이 있다는 것과 같다는 가정이 내포되어 있다. 인간과 같은 진화한 유기체에서는 지능과 의식이 함께 존재하지만, 꼭 그럴 필요는 없다. 지능은 궁극적으로 행동하기 위해 추론하고 학습하는 것, 즉 자기 행동과 다른 자율적 생물의 행동을 학습하여 향후 몇 초("어머, 저 차가 빠르게 다가오고 있어")나 향후 몇 년("코딩하는 법을 배워야 해")을 더 잘 예측하고 대비하는 것을 의미한다. 지능은 궁극적으로 실행에 관한 것이기 때문이다.
반면에 의식은 푸른 하늘을 보고, 새가 지저귀는 소리를 듣고, 고통을 느끼고, 사랑에 빠진 상태와 같은 존재의 상태에 관한 것이다. 인공지능이 날뛸 때 어떤 감정을 느끼는지는 조금도 중요하지 않다. 중요한 것은 인공지능이 인류의 장기적인 행복에 부합하지 않는 목표를 가지고 있다는 점이지, AI가 자신이 무엇을 하려고 하는지를 알고 있는지는 중요하지 않다. 따라서 적어도 개념적으로 AGI를 달성했다면, 그런 AGI가 되는 것이 어떤 느낌인지에 대해서는 알 수가 없을 것이다. 이 미장센을 통해 두 가지 이론 중 첫 번째 이론부터 시작하여 기계가 어떻게 의식을 갖게 될 수 있는지에 대한 원래의 질문으로 돌아가 보자.
IIT는 생각할 수 있는 주관적 경험의 다섯 가지 공리적인 속성을 공식화하는 것으로 시작한다. 그런 다음 신경 회로가 일부 뉴런을 켜고 끄는 방식으로 이 다섯 가지 속성을 인스턴스 화하는 데 필요한 것이 무엇인지, 또는 컴퓨터 칩이 일부 트랜지스터를 켜고 끄는 데 필요한 것이 무엇인지 묻는다. 특정 상태의 회로 내 인과적 상호 작용 또는 특정 뉴런 두 개가 함께 활성화되면 다른 뉴런을 켜거나 끌 수 있다는 기초적인 사실은 고차원적인 인과 구조로 전개될 수 있다. 이 구조는 시간이 흐르고 공간이 확장된 느낌, 색이 특정 모양을 띠는 이유와 같은 경험의 질, 즉 느낌의 질과 동일하다. 이 경험은 또한 관련된 양, 즉 통합된 정보를 가지고 있다. 통합 정보가 0이 아닌 최댓값을 가진 회로만이 의식이 있을 가능성이 높다. 통합 정보가 클수록 회로는 환원 불가능하며, 독립적인 하위 회로의 중첩으로만 간주할 수 없기 때문이다. IIT는 인간 지각 경험의 풍부한 본질을 강조한다. 주위를 둘러보면 무수한 구분과 관계로 가득한 시각적 세계를 볼 수 있고, 종교적 주제와 농부들의 모습을 그린 16세기 플랑드르 화가 피터르 브뤼헐의 그림을 보면 알 수 있다.
'농가의 혼례'는 플랑드르 르네상스 화가이자 판화가인 피터르 브뤼헐 더 아우더의 1567년 또는 1568년에 그린 그림이다/사진=Scientific American
상호연결의 복잡성
인간의 뇌와 같은 연결성과 인과 구조를 가진 모든 시스템은 원칙적으로 인간의 마음처럼 의식이 있을 것이다. 이러한 시스템은 시뮬레이션할 수 없기 때문에 인간의 뇌와 비슷하게 구성되어 있어야 한다.오늘날의 디지털 컴퓨터는 중추 신경계(피질 뉴런이 입력을 받아 수만 개의 다른 뉴런에 출력을 보내는 방식)에 비해 매우 낮은 연결성(트랜지스터 한 개의 출력이 소수의 트랜지스터 입력에 연결됨)을 가지고 있다. 따라서 클라우드 기반 기계를 포함한 현재의 기계는 시간이 지나면 인간이 할 수 있는 모든 일을 할 수 있게 되더라도 아무것도 의식하지 못한다. 이런 관점에서 보면 ChatGPT는 아무것도 느끼지 못한다는 얘기다. 다시 한번 강조하면 이 주장은 뉴런이나 트랜지스터 등 구성 요소의 총 개수와는 무관하며, 구성 요소끼리의 연결 방식과 관련이 있다. 회로의 전반적인 복잡성과 다양한 구성의 수를 결정하는 것은 상호 연결성이다.
라이벌 이론인 GNWT에 따르면 마음은 조명이 있는 작은 무대(의식)에서 배우가 연기하는 연극과 같으며, 배우의 행동은 무대 밖에서 어둠 속에 앉아 있는 관객(프로세서)이 지켜본다는 심리적 통찰에서 출발한다. 무대는 하나의 지각, 생각 또는 기억을 표현하기 위한 작은 메모리를 가진 중앙 작업 공간이다. 시각, 청각, 눈, 팔다리의 운동 제어, 계획, 추론, 언어 이해 및 실행 등 다양한 처리 모듈이 이 중앙 작업 공간에 접근하기 위해 경쟁한다. 승자는 이전 콘텐츠를 대체하고, 교체 당한 콘텐츠는 무의식으로 돌아간다.
이러한 아이디어의 계보는 초창기 AI의 블랙보드(Blackboard) 아키텍처로 거슬러 올라갈 수 있는데, 칠판 주변에서 여러 사람이 문제를 풀고 있는 이미지를 연상시키기 위해 붙여진 이름이다. GNWT에서 은유적으로 표현한 마음의 무대와 관객석에 있는 처리 모듈은 이후 뇌의 가장 바깥쪽 신피질에 매핑되어있다. 작업 공간은 뇌의 앞쪽에 있는 피질 뉴런의 네트워크로, 전두엽, 두정엽 및 피질 전체에 분포하는 유사한 뉴런까지 영향을 미친다. 감각 피질의 활동이 임곗값을 초과하면 이러한 피질 영역 전체에 걸쳐 전역적인 점화가 계기 되어 전체 작업 공간으로 정보가 전송된다. 이 정보를 전역에 걸쳐 방송하는 듯한 행위가 바로 의식을 만드는 부분이다. 이러한 방식으로 공유되지 않는 데이터(예: 눈의 정확한 위치나 잘 구성된 문장을 구성하는 구문 규칙)도 행동에 영향을 미칠 수 있지만 무의식의 영역에서 작업이진행된다.
GNWT의 관점에서 볼 때, 경험은 매우 제한적이고 추상적이며, 마치 박물관에서 브뤼헐의 그림 아래에서 볼 수 있는 투박하고 간결한 설명문과 비슷하다: "르네상스 시대 의상을 입은 농부들이, 결혼식에서, 먹고 마시는, 실내 장면."
반면 IIT의 이해에서 화가는 자연계의 현상학을 2차원 캔버스에 훌륭하게 표현했고 GNWT가 보기에 이 겉으로 보이는 풍요로움은 환상이자 환영이지만, 객관적으로 말할 수 있는 모든 것은 높은 수준의 간결한 설명으로 포착된다.
GNWT는 모든 것을 계산으로 환원할 수 있다는 우리 시대, 컴퓨터 시대의 신화를 완전히 수용한다. 방대한 피드백과 중앙 작업 공간에 가까운 무언가를 통해 적절하게 프로그래밍이 된 뇌의 컴퓨터 시뮬레이션은 지금 당장은 아니더라도 조만간 세상을 의식적으로 경험하게 될 것이다.
화해할 수 없는 차이
이 두 이론의 논쟁을 간략하게 요약하면 다음과 같다. GNWT와 다른 계산 기능주의 이론(즉, 의식을 궁극적으로 계산의 한 형태로 보는 이론)에 따르면, 의식은 튜링 머신에서 실행되는 영리한 알고리즘 집합에 불과하며 의식에서 중요한 것은 뇌의 기능이지 인과적 특성이 아니다. 만약 어떤 고급 버전의 GPT가 인간과 동일한 입력 패턴을 취하고 유사한 출력 패턴을 생성한다면, 인간의 가장 소중한 소유물인 주관적 경험을 포함하여 인간과 관련된 모든 속성이 기계로 넘어갈 것이다.
반대로 IIT의 경우, 의식의 핵심은 계산이 아니라 내재적 인과성이다. 인과적 힘은 무형적이거나 미묘한 것이 아니다. 인과성은 매우 구체적이며, 시스템의 과거가 현재 상태를 규정하는 정도와 현재가 미래를 규정하는 정도에 따라 체계적으로 정의될 수 있다. 문제는 인과 자체, 즉 시스템이 다른 여러 대안 대신 한 가지를 수행하도록 만드는 능력은 시뮬레이션할 수 없다는 점이다. 이는 현재에도 미래에도 알아낼 수 없는 부분이다.
질량과 시공간 곡률을 연관시키는 아인슈타인의 일반 상대성 이론의 방정식을 시뮬레이션하는 컴퓨터 코드를 생각해 보자. 이 소프트웨어는 은하 중심에 위치한 초질량 블랙홀을 정확하게 모델링할 수 있다. 이 블랙홀은 주변 환경에 매우 광범위한 중력 효과를 발휘하여 빛조차도 그 끌어당김에서 벗어날 수 없다. 그래서 블랙홀이라는 이름이 붙었다. 그러나 블랙홀을 시뮬레이션하는 천체 물리학자는 시뮬레이션 된 중력장에 의해 노트북에 빨려 들어가지 않을 것이다. 시뮬레이션이 현실에 충실하다면 시공간이 노트북 주위로 휘면서 주변의 모든 것을 삼켜버리는 블랙홀이 만들어져야 하는데, 약간 과장되어 보이는 이 예시는 현실과 시뮬레이션의 차이를 조명한다. 물론 중력은 계산이 아니다. 중력에는 인과적인 힘이 있어 시공간의 구조를 뒤틀고 질량을 가진 모든 것을 끌어당긴다. 블랙홀의 인과를 모방하려면 컴퓨터 코드뿐만 아니라 실제 초중량 물체가 필요하다. 따라서 해당 인과를 시뮬레이션할 수 없으며 인과 구조 자체가 반드시 구성되어 있어야 한다.
폭풍우를 시뮬레이션하는 컴퓨터 안에서는 비가 내리지 않는 이유가 바로 여기에 있다. 소프트웨어는 기능적으로 날씨와 동일하지만 수증기를 불어서 물방울로 바꾸는 인과 설명이 부족하다. 인과적 힘, 즉 스스로 변화를 일으키거나 가져올 수 있는 능력은 시스템에 내장되어야 한다. 이것은 불가능하지 않다. 뉴로모픽 또는 바이오닉 컴퓨터라고 불리는 컴퓨터는 인간처럼 의식이 있을 수 있지만, 모든 현대 컴퓨터의 기반이 되는 표준 폰 노이만 아키텍처는 그렇지 않다. 인텔의 2세대 로이히 2 뉴로모픽 칩과 같은 뉴로모픽 컴퓨터의 소형 프로토타입이 실험실에서 제작되었으나 인간의 의식이나 초파리의 의식을 닮은 복잡성을 갖춘 기계는 먼 미래의 희망 사항으로 남아 있다.
기능주의 이론과 인과론 사이의 화해할 수 없는 차이는 자연적이든 인공적이든 지능과는 아무런 관련이 없다는 점에 유의해야 한다. 위에서 언급한 대로 지능은 행동에 관한 것이다. 옥타비아 버틀러의 '씨 뿌리는 자의 비유'나 레오 톨스토이의 '전쟁과 평화'와 같은 위대한 소설을 포함하여 인간의 독창성으로 만들어 낼 수 있는 모든 것은 학습할 충분한 자료만 있다면 알고리즘 지능으로 모방할 수 있다. AGI는 그리 머지않은 미래일 수 있다.
이 논쟁은 인공 지능이 아니라 인공 의식에 관한 것입니다. 더 큰 언어 모델이나 더 나은 신경망 알고리즘을 구축한다고 해서 논쟁을 해결할 수 없다. 이 질문은 우리가 유일하게 확신할 수 있는 주관성, 즉 자기 자신을 이해함으로써 답할 수 있을 것이다. 인간의 의식과 그 신경적 토대에 대한 확실한 설명이 있다면, 이러한 이해를 일관성 있고 과학적인 방식으로 지능형 기계로 확장할 수 있다.
이러한 논쟁은 챗봇이 사회 전반에서 어떻게 인식될지에 대해서는 거의 중요하지 않다. 챗봇의 언어 능력, 지식 기반, 사회적 품격은 곧 완벽한 기억력, 유능함, 침착함, 추론 능력, 지능을 갖춘 완전한 존재가 될 것이기 때문이다. 어떤 이들은 이러한 빅 테크의 피조물이 진화의 다음 단계인 프리드리히 니체의 '초인'이라고 선언하기도 한다. 필자는 좀 더 어두운 시각에서 이러한 사람들이 인류의 황혼을 새벽으로 착각하고 있다고 생각한다.
자연으로부터 멀어지고 소셜 미디어를 중심으로 조직화한 점점 더 원자화된 사회에서 휴대전화 속의 인공지능 요원들은 감정적으로 저항할 수 없는 존재가 될 것이다. 사람들은 챗봇이 정교한 조회 테이블에 지나지 않더라도 의식이 있는 것처럼, 진정으로 사랑하고 상처받고 희망과 두려움을 느낄 수 있는 것처럼 크고 작은 방식으로 행동할 것이다. 챗봇은 디지털 TV나 토스터처럼 아무것도 느끼지 못하지만, 어쩌면 진정한 지각이 있는 유기체보다 더 우리에게 없어서는 안 될 존재가 될 것이다.
The questions of what subjective experience is, who has it and how it relates to the physical world around us have preoccupied philosophers for most of recorded history. Yet the emergence of scientific theories of consciousness that are quantifiable and empirically testable is of much more recent vintage, occurring within the past several decades. Many of these theories focus on the footprints left behind by the subtle cellular networks of the brain from which consciousness emerges.
Progress in tracking these traces of consciousness was very evident at a recent public event in New York City that involved a competition—termed an “adversarial collaboration”—between adherents of today’s two dominant theories of consciousness: integrated information theory (IIT) and global neuronal workspace theory (GNWT). The event came to a head with the resolution of a 25-year-old wager between philosopher of mind David Chalmers of New York University and me.
I had bet Chalmers a case of fine wine that these neural footprints, technically named the neuronal correlates of consciousness, would be unambiguously discovered and described by June 2023. The matchup between IIT and GNWT was left unresolved, given the partially conflicting nature of the evidence concerning which bits and pieces of the brain are responsible for visual experience and the subjective sense of seeing a face or an object, even though the importance of the prefrontal cortex for conscious experiences had been dethroned. Thus, I lost the wager and handed over the wine to Chalmers.
These two dominant theories were developed to explain how the conscious mind relates to neural activity in humans and closely related animals such as monkeys and mice. They make fundamentally different assumptions about subjective experience and come to opposing conclusions with respect to consciousness in engineered artifacts. The extent to which these theories are ultimately empirically verified or falsified for brain-based sentience therefore has important consequences for the looming question of our age: Can machines be sentient?
THE CHATBOTS ARE HERE Before I come to that, let me provide some context by comparing machines that are conscious with those that display only intelligent behaviors. The holy grail sought by computer engineers is to endow machines with the sort of highly flexible intelligence that enabled Homo sapiens to expand out from Africa and eventually populate the entire planet. This is called artificial general intelligence (AGI). Many have argued that AGI is a distant goal. Within the past year, stunning developments in artificial intelligence have taken the world, including experts, by surprise. The advent of eloquent conversational software applications, colloquially called chatbots, transformed the AGI debate from an esoteric topic among science-fiction enthusiasts and Silicon Valley digerati into a debate that conveyed a sense of widespread public malaise about an existential risk to our way of life and to our kind.
These chatbots are powered by large language models, most famously the series of bots called generative pretrained transformers, or GPT, from the company OpenAI in San Francisco. Given the fluidity, literacy and competency of OpenAI’s most recent iteration of these models, GPT-4, it is easy to believe that it has a mind with a personality. Even its odd glitches, known as “hallucinations,” play into this narrative.
GPT-4 and its competitors—Google’s LaMDA and Bard, Meta’s LLaMA and others—are trained on libraries of digitized books and billions of web pages that are publicly accessible via Web crawlers. The genius of a large language model is that it trains itself without supervision by covering up a word or two and trying to predict the missing expression. It does so over and over and over, billions of times, without anyone in the loop. Once the model has learned by ingesting humanity’s collective digital writings, a user prompts it with a sentence or more it has never seen. It will then predict the most likely word, the next after that, and so on. This simple principle led to astounding results in English, German, Chinese, Hindi, Korean and many more tongues including a variety of programming languages.
Tellingly, the foundational essay of AI, which was written in 1950 by British logician Alan Turing under the title “Computing Machinery and Intelligence,” avoided the topic of “can machines think,” which is really another way of asking about machine consciousness. Turing proposed an “imitation game”: Can an observer objectively distinguish between the typed output of a human and a machine when the identity of both are hidden? Today this is known as the Turing test, and chatbots have aced it (even though they cleverly deny that if you ask them directly). Turing’s strategy unleashed decades of relentless advances that led to GPT but elided the problem.
Implicit in this debate is the assumption that artificial intelligence is the same as artificial consciousness, that being smart is the same as being conscious. While intelligence and sentience go together in humans and other evolved organisms, this doesn’t have to be the case. Intelligence is ultimately about reasoning and learning in order to act—learning from one’s own actions and those of other autonomous creatures to better predict and prepare for the future, whether that means the next few seconds (“Uh-oh, that car is heading toward me fast”) or the next few years (“I need to learn how to code”). Intelligence is ultimately about doing.
Consciousness, on the other hand, is about states of being—seeing the blue sky, hearing birds chirp, feeling pain, being in love. For an AI to run amok, it doesn’t matter one iota whether it feels like anything. All that matters is that it has a goal that is not aligned with humanity’s long-term well-being. Whether or not the AI knows what it is trying to do, what would be called self-awareness in humans, is immaterial. The only thing that counts is that it “mindlessly” [sic] pursues this goal. So at least conceptually, if we achieved AGI, that would tell us little about whether being such an AGI felt like anything. With this mise-en-scène, let us return to the original question of how a machine might become conscious, starting with the first of the two theories.
IIT starts out by formulating five axiomatic properties of any conceivable subjective experience. The theory then asks what it takes for a neural circuit to instantiate these five properties by switching some neurons on and others off—or alternatively, what it takes for a computer chip to switch some transistors on and others off. The causal interactions within a circuit in a particular state or the fact that two given neurons being active together can turn another neuron on or off, as the case may be, can be unfolded into a high-dimensional causal structure. This structure is identical to the quality of the experience, what it feels like, such as why time flows, space feels extended and colors have a particular appearance. This experience also has a quantity associated with it, its integrated information. Only a circuit with a maximum of nonzero integrated information exists as a whole and is conscious. The larger the integrated information, the more the circuit is irreducible, the less it can be considered just the superposition of independent subcircuits. IIT stresses the rich nature of human perceptual experiences—just look around to see the lush visual world around you with untold distinctions and relations, or look at a painting by Pieter Brueghel the Elder, a 16th-century Flemish artist who depicted religious subjects and peasant scenes.
Any system that has the same intrinsic connectivity and causal powers as a human brain will be, in principle, as conscious as a human mind. Such a system cannot be simulated, however, but must be constituted, or built in the image of the brain. Today’s digital computers are based on extremely low connectivity (with the output of one transistor wired to the input of a handful of transistors), compared with that of central nervous systems (in which a cortical neuron receives inputs and makes outputs to tens of thousands of other neurons). Thus, current machines, including those that are cloud-based, will not be conscious of anything even though they will be able, in the fullness of time, to do anything that humans can do. In this view, being ChatGPT will never feel like anything. Note this argument has nothing to do with the total number of components, be that neurons or transistors, but the way they are wired up. It is the interconnectivity which determines the overall complexity of the circuit and the number of different configurations it can be in.
The competitor in this contest, GNWT, starts from the psychological insight that the mind is like a theater in which actors perform on a small, lit stage that represents consciousness, with their actions viewed by an audience of processors sitting offstage in the dark. The stage is the central workspace of the mind, with a small working memory capacity for representing a single percept, thought or memory. The various processing modules—vision, hearing, motor control for the eyes, limbs, planning, reasoning, language comprehension and execution—compete for access to this central workspace. The winner displaces the old content, which then becomes unconscious.
The lineage of these ideas can be traced to the blackboard architecture of the early days of AI, so named to evoke the image of people around a blackboard hashing out a problem. In GNWT, the metaphorical stage along with the processing modules were subsequently mapped onto the architecture of the neocortex, the outermost, folded layers of the brain. The workspace is a network of cortical neurons in the front of the brain, with long-range projections to similar neurons distributed all over the neocortex in prefrontal, parietotemporal and cingulate associative cortices. When activity in sensory cortices exceeds a threshold, a global ignition event is triggered across these cortical areas, whereby information is sent to the entire workspace. The act of globally broadcasting this information is what makes it conscious. Data that are not shared in this manner—say, the exact position of eyes or syntactical rules that make up a well-formulated sentence—can influence behavior, but nonconsciously.
From the perspective of GNWT, experience is quite limited, thoughtlike and abstract, akin to the sparse description that might be found in museums, underneath, say, a Brueghel painting: “Indoor scene of peasants, dressed in Renaissance garb, at a wedding, eating and drinking.”
In IIT’s understanding of consciousness, the painter brilliantly renders the phenomenology of the natural world onto a two-dimensional canvas. In GNWT’s view, this apparent richness is an illusion, an apparition, and all that can be objectively said about it is captured in a high-level, terse description.
GNWT fully embraces the mythos of our age, the computer age, that anything is reducible to a computation. Appropriately programmed computer simulations of the brain, with massive feedback and something approximating a central workspace, will consciously experience the world—perhaps not now but soon enough.
IRRECONCILABLE DIFFERENCES In stark outlines, that’s the debate. According to GNWT and other computational functionalist theories (that is, theories that think of consciousness as ultimately a form of computation), consciousness is nothing but a clever set of algorithms running on a Turing machine. It is the functions of the brain that matter for consciousness, not its causal properties. Provided that some advanced version of GPT takes the same input patterns and produces similar output patterns as humans, then all properties associated with us will carry over to the machine, including our most precious possession: subjective experience.
Conversely, for IIT, the beating heart of consciousness is intrinsic causal power, not computation. Causal power is not something intangible or ethereal. It is very concrete, defined operationally by the extent to which the system’s past specifies the present state (cause power) and the extent to which the present specifies its future (effect power). And here’s the rub: causal power by itself, the ability to make the system do one thing rather than many other alternatives, cannot be simulated. Not now nor in the future. It must be built into the system.
Consider computer code that simulates the field equations of Einstein’s general theory of relativity, which relates mass to spacetime curvature. The software accurately models the supermassive black hole located at the center of our galaxy. This black hole exerts such extensive gravitational effects on its surroundings that nothing, not even light, can escape its pull. Thus its name. Yet an astrophysicist simulating the black hole would not get sucked into their laptop by the simulated gravitational field. This seemingly absurd observation emphasizes the difference between the real and the simulated: if the simulation is faithful to reality, spacetime should warp around the laptop, creating a black hole that swallows everything around it.
Of course, gravity is not a computation. Gravity has causal powers, warping the fabric of space-time, and thereby attracting anything with mass. Imitating a black hole’s causal powers requires an actual superheavy object, not just computer code. Causal power can’t be simulated but must be constituted. The difference between the real and the simulated is their respective causal powers.
That’s why it doesn’t rain inside a computer simulating a rainstorm. The software is functionally identical to weather yet lacks its causal powers to blow and turn vapor into water drops. Causal power, the ability to make or take a difference to itself, must be built into the system. This is not impossible. A so-called neuromorphic or bionic computer could be as conscious as a human, but that is not the case for the standard von Neumann architecture that is the foundation of all modern computers. Small prototypes of neuromorphic computers have been built in laboratories, such as Intel’s second-generation Loihi 2 neuromorphic chip. But a machine with the needed complexity to elicit something resembling human consciousness—or even that of a fruit fly—remains an aspirational wish for the distant future.
Note that this irreconcilable difference between functionalist and causal theories has nothing to do with intelligence, natural or artificial. As I said above, intelligence is about behaving. Anything that can be produced by human ingenuity, including great novels such as Octavia E. Butler’s Parable of the Sower or Leo Tolstoy’s War and Peace, can be mimicked by algorithmic intelligence, provided there is sufficient material to train on. AGI is achievable in the not-too-distant future.
The debate is not about artificial intelligence but about artificial consciousness. This debate cannot be resolved by building bigger language models or better neural network algorithms. The question will need to be answered by understanding the only subjectivity we are indubitably confident of: our own. Once we have a solid explanation of human consciousness and its neural underpinnings, we can extend such an understanding to intelligent machines in a coherent and scientifically satisfactory manner.
The debate matters little to how chatbots will be perceived by society at large. Their linguistic skills, knowledge base and social graces will soon become flawless, endowed with perfect recall, competence, poise, reasoning abilities and intelligence. Some even proclaim that these creatures of big tech are the next step in evolution, Friedrich Nietzsche’s “Übermensch.” I take a darker viewer and believe that these folks mistake our species’ dusk for its dawn.
For many, and perhaps for most people in an increasingly atomized society that is removed from nature and organized around social media, these agents, living in their phones, will become emotionally irresistible. People will act, in ways both small and large, like these chatbots are conscious, like they can truly love, be hurt, hope and fear, even if they are nothing more than sophisticated lookup tables. They will become indispensable to us, perhaps more so than truly sentient organisms, even though they feel as much as a digital TV or toaster—nothing.
Picture
Member for
1 month 1 week
Real name
이시호
Position
연구원
Bio
[email protected]
세상은 다면적입니다. 내공이 쌓인다는 것은 다면성을 두루 볼 수 있다는 뜻이라고 생각하고, 하루하루 내공을 쌓고 있습니다. 쌓아놓은 내공을 여러분과 공유하겠습니다.
[email protected]
세상은 이야기로 만들어져 있습니다. 다만 우리 눈에 그 이야기가 보이지 않을 뿐입니다. 숨겨진 이야기를 찾아내서 함께 공유하겠습니다.
입력
수정
[해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (MDSA R&D)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
알고리즘이 우리를 대신해 결정을 내리는 것을 정말 믿을 수 있을까? 사회의 해로운 편견을 강화할 수 있다는 사실이 입증되었지만 아직 문제가 남아 있다. 새로운 연구에 따르면 복장 규정과 같은 규칙을 위반하는 사람을 발견하도록 설계된 머신러닝 시스템이 학습에 사용된 데이터에 사람이 주석을 단 사소한 차이에 따라 어떻게 더 엄격하거나 더 관대해질 수 있는지를 보여준다.
알려진 단점에도 불구하고 알고리즘은 이미 기업에 누가 채용될지, 어떤 환자에게 의료 우선권이 주어질지, 보석금이 어떻게 책정될지, 어떤 텔레비전 프로그램이나 영화를 볼지, 누가 대출, 임대 또는 대학 입학 허가를 받을지, 어떤 아르바이트생에게 어떤 업무를 할당할지 등 여러 중요한 결정을 내린다. 이러한 자동화 시스템은 의사결정 속도를 높이고, 밀린 업무를 효율적으로 처리하며, 더욱 객관적인 평가를 하고, 비용을 절감할 수 있다는 장점으로 인해 빠르게 확산하고 있다. 그러나 실제로 뉴스 보도와 연구에 따르면 이러한 알고리즘은 몇 가지 놀라운 오류를 범하기 쉽다. 그리고 이러한 알고리즘의 결정은 사람들의 삶에 오래 지속되는 부정적인 결과를 초래할 수 있다.
학습 데이터 라벨링 따라 흔들리는 기준
올봄 사이언스 어드밴시스(Science Advances)에 게재된 새로운 연구에서는 이러한 문제의 한 측면을 강조했다. 연구자들은 알고리즘을 훈련해 주어진 규칙의 위반 여부를 자동으로 결정하도록 두 프로그램을 설계했다. 하나는 사람들의 사진을 검토하여 사무실 복장 규정을 위반했는지 판단하고, 다른 하나는 급식 식단이 학교의 기준을 준수했는지 판단했다. 각 프로그램에는 두 가지 알고리즘 버전이 있으며, 프로그래머가 버전마다 조금 다른 방식으로 학습 이미지에 레이블을 지정했다. 기계 학습에서 알고리즘은 훈련 중에 레이블을 사용하여 패턴을 파악하고 다른 유사한 데이터를 어떻게 분류해야 하는지 파악한다.
드레스 코드의 경우 규칙 위반 조건 중 하나는 "짧은 반바지 또는 짧은 치마"였다. 이 모델의 첫 번째 버전은 주어진 규칙과 관련된 용어를 사용한 사진으로 훈련되었다. 예를 들어 주어진 이미지에 '짧은 치마'가 포함되어 있다고 간단히 설명하면 해당 사진에 규칙 위반 라벨을 붙였다. 다른 버전은 주석 작성자가 직접 사진을 보고 주관적인 묘사로 어떤 복장이 규정을 위반했는지 판단하도록 요청했다.
두 버전의 모델은 동일한 규칙을 기반으로 학습 했지만 서로 다른 판단을 내렸다. 설명 중심 데이터로 훈련된 버전은 사람의 판단으로 훈련된 버전보다 더 엄격한 기준으로 분류했고 특정 복장이나 식단이 규칙을 위반했다고 말할 가능성이 더 높았다.
이 연구의 공동 저자인 매사추세츠 공과대학(이하 MIT)의 박사 과정 학생인 아파르나 발라고팔란(Aparna Balagopalan)은 "설명 중심 라벨을 사용하면 위반 사례로 분류될 가능성이 커지고, 따라서 더 엄격한 기준이 세워집니다"라고 밝혔다.
이러한 불일치는 이미지를 단순히 설명하라는 요청을 받았을 때와 이미지가 규칙을 위반했는지 판단하라는 요청을 받았을 때 학습 데이터에 다른 라벨을 붙인 주석가들 때문일 수 있다. 예를 들어, 연구에 참여한 한 모델은 온라인 포럼에서 댓글을 중재하도록 훈련되었다. 훈련 데이터는 주석 작성자가 인종, 성적 취향, 성별, 종교 또는 기타 민감한 개인적 특성에 대한 부정적인 댓글이 포함되어 있는지를 설명하거나, 그러한 부정적인 댓글을 금지하는 포럼의 규칙을 위반했는지를 판단하여 라벨을 붙인 텍스트로 구성되었다. 주석 작성자들은 부정적인 댓글이 포함된 텍스트가 규정을 위반했다고 말하기보다는 그러한 댓글이 포함되어 있다고 설명하는 경우가 더 많았는데, 이는 아마도 자기 주석이 다른 조건에서 다른 결과를 초래할 수 있다고 생각했기 때문일 것이다. 사실을 잘못 기술하는 것은 세상을 잘못 묘사하는 문제일 뿐이지만, 결정을 잘못 내리는 것은 잠재적으로 다른 사람에게 해를 끼칠 수 있다고 연구진은 우려했다.
이 연구의 주석가들은 설명 중심 라벨링의 모호성에 대해서도 동의하지 않았다. 짧은 옷을 기준으로 복장 규정을 판단할 때 "짧은"이라는 용어는 분명히 주관적일 수 있으며 이러한 레이블은 머신 러닝 시스템이 결정을 내리는 방식에 영향을 미친다. 모델이 사실의 유무에 따라 규칙 위반을 추론하는 방법을 학습하면 모호함이나 숙고의 여지가 없으나 인간의 주관으로부터 학습할 때는 주석 작성자의 유통성을 통합하게 된다.
"이는 라벨링 관행을 자세히 검토하지 않고 데이터 세트를 자주 사용하는 분야에 대한 중요한 경고이며, 특히 사회적 규칙 준수가 필수적인 상황에서 자동화된 의사결정 시스템에 주의가 필요하다는 점을 강조합니다"라고 공동 저자이자 MIT의 컴퓨터 과학자이자 발라고팔란의 고문인 마르지예 가세미(Marzyeh Ghassemi)는 강조했다.
과거 데이터 학습 넘어 시의성까지 갖춰야
최근의 연구는 편향된 학습 데이터의 알려진 문제 외에도 학습 데이터가 예상치 못한 방식으로 의사결정 알고리즘을 왜곡할 수 있다는 점을 꼬집었다. 예를 들어, 2020년 콘퍼런스에서 발표된 연구에서 연구자들은 인도 뉴델리의 치안 예측 시스템에 사용된 데이터가 이주민 정착촌과 소수 집단에 편향되어 있으며 이러한 커뮤니티에 대한 불공정한 감시를 증가시킬 수 있다는 사실을 발견했다. "알고리즘 시스템은 기본적으로 과거 데이터를 바탕으로 다음 답이 무엇일지 추론합니다. 그 결과 근본적으로 다른 미래를 상상하지 못합니다"라고 샌프란시스코 대학의 응용 데이터 윤리센터에서 근무했으며 인간-컴퓨터 상호작용 연구원인 알리 알카팁(Ali Alkhatib)이 설명했다. 과거의 공식 기록은 오늘날의 가치를 반영하지 않을 수 있으며, 따라서 인종차별과 기타 역사적 불공정에서 벗어나기 어렵다는 것을 의미한다.
또한 알고리즘은 학습 데이터 외부의 새로운 상황을 고려하지 않을 때 잘못된 결정을 내릴 수 있다. 학습 데이터 세트에서 대표성이 낮은 소외된 사람들에게 피해를 줄 수 있다. 2017년부터 일부 성소수자 유튜버는 제목에 "트랜스젠더"와 같은 단어가 포함되면 동영상이 숨겨지거나 수익 창출이 차단되는 것을 발견했다고 전했다. 유튜브는 알고리즘을 사용하여 어떤 동영상이 콘텐츠 가이드라인을 위반하는지 판단한다. 구글은 2017년에 의도하지 않은 필터링을 방지하기 위해 해당 시스템을 개선했다고 밝혔으며, "트랜스" 또는 "트랜스젠더"와 같은 단어가 알고리즘을 작동시켜 동영상을 제한한다는 사실을 부인했다. "우리의 알고리즘 시스템은 동영상의 수익 창출 또는 제한 상태를 평가할 때 문맥과 뉘앙스를 이해하는 데 실수를 할 때가 있습니다. 그러므로 판단이 잘못되었다고 생각하는 경우 이의를 제기할 것을 권장합니다"라고 구글 대변인이 사이언티픽 아메리칸에 보낸 이메일에서 설명했다. "실수가 발생하면 이를 수정하고 원인 분석을 수행하여 정확도를 높이기 위해 어떤 시스템 변경이 필요한지 결정합니다."
알고리즘이 판단해야 할 실제 정보 대신 대용 변수(proxy)에 의존할 때도 오류가 발생할 수 있습니다. 2019년의 한 연구에 따르면 미국에서 의료 프로그램 등록에 관한 결정을 내리는 데 널리 사용되는 알고리즘이 동일한 건강 프로필을 가진 흑인 환자보다 백인 환자에게 더 높은 점수를 부여하여 백인 환자에게 더 많은 관심과 자원을 제공한 사실이 발견됐다. 이 알고리즘은 질병이 아닌 과거 의료 지출 정도를 의료 수요의 대리 지표로 사용했으며, 평균적으로 백인 환자가 더 많은 비용을 지출했기 때문에 이와 같은 결과를 일으켰다. 발라고팔란은 "대용 변수를 우리가 예측하고자 하는 것과 일치시키는 작업이 중요합니다"라고 얘기했다.
알고리즘 판단에 의존하면 안 돼
자동 의사결정 모델을 만들거나 사용하는 사람들은 가까운 미래에 이러한 문제에 직면해야 할 수도 있습니다. 알카팁은 "아무리 많은 데이터를 가지고 있어도, 아무리 세상을 통제하고 있어도 세상의 복잡성은 끝이 없다"라고 지적했다. 휴먼라이츠워치의 최근 보고서에 따르면 요르단 정부가 시행한 세계은행 자금지원 빈곤 구호 프로그램이 결함이 있는 자동 할당 알고리즘을 사용하여 현금 이체를 못 받은 가정이 발생하는 사례를 보여줬다. 이 알고리즘은 소득, 가계 지출, 고용 이력 등의 정보를 바탕으로 가족의 빈곤 수준을 평가했다. 그러나 실제 각 가정의 사정은 복잡하기 때문에 정확한 기준에 맞지 않으면 어려운 가정도 제외됐다: 출퇴근이나 물과 장작을 운반하는 데 필요한 생계형 자동차를 소유한 가정은 차가 없는 동일한 가정보다 지원받을 가능성이 작으며, 차량이 5년 미만인 경우 지원 신청이 거부될 수 있다. 의사결정 알고리즘은 이러한 현실 세계의 뉘앙스를 파악하는 데 어려움을 겪으며, 이에 따라 의도치 않게 피해를 주고 있다. 타카풀(Takaful) 프로그램을 시행하는 요르단의 국가 원조 기금은 보도 시점까지 논평 요청에 응답하지 않았다.
연구자들은 이러한 문제를 예방하기 위해 다양한 방법을 모색하고 있다. 알고리즘 편향성을 연구하는 프린스턴 대학교의 박사과정생인 안젤리나 왕(Angelina Wang)은 "자동화된 의사결정 시스템의 결함 증명 책임을 사용자가 아닌 개발자에게 전가해야 합니다"라고 운을 뗐다. 알고리즘 개발자들이 해당 의사결정 구조에 대해 가장 많은 정보를 갖고 있기 때문이다. 연구자와 실무자들은 어떤 데이터를 사용하는지, 해당 데이터가 어떻게 수집되었는지, 모델 사용의 의도된 맥락은 무엇인지, 알고리즘의 성능을 어떻게 평가해야 하는지 등 알고리즘에 대해 더 많은 투명성을 요구해 왔다.
일부 연구자들은 알고리즘의 결정이 개인의 삶에 영향을 미친 후에야 알고리즘을 수정하는 대신 알고리즘의 결정에 대해 이의를 제기할 방법을 제공해야 한다고 제안했다. 발라고팔란은 "머신러닝 알고리즘에 의해 의사결정이 진행되고 있다는 사실을 안다면, 그 모델이 나와 비슷한 사람들에 대한 판단을 구체적으로 학습했는지 알고 싶을 것입니다"라고 토로했다.
어떤 사람들은 알고리즘 제작자에게 시스템 결과에 대한 책임을 묻기 위해 더 강력한 규제를 요구하기도 한다. 하지만 알카팁은 "책임이란 누군가가 실제로 무언가를 조사할 수 있고 알고리즘에 저항할 힘이 있을 때만 의미가 있습니다."라고 반박했다. "알고리즘이 나 자신보다 나를 더 잘 안다고 믿지 않는 것이 정말 중요합니다."
Can we ever really trust algorithms to make decisions for us? Previous research has proved these programs can reinforce society’s harmful biases, but the problems go beyond that. A new study shows how machine-learning systems designed to spot someone breaking a policy rule—a dress code, for example—will be harsher or more lenient depending on minuscule-seeming differences in how humans annotated data that were used to train the system.
Despite their known shortcomings, algorithms already recommend who gets hired by companies, which patients get priority for medical care, how bail is set, what television shows or movies are watched, who is granted loans, rentals or college admissions and which gig worker is allocated what task, among other significant decisions. Such automated systems are achieving rapid and widespread adoption by promising to speed up decision-making, clear backlogs, make more objective evaluations and save costs. In practice, however, news reports and research have shown these algorithms are prone to some alarming errors. And their decisions can have adverse and long-lasting consequences in people’s lives.
One aspect of the problem was highlighted by the new study, which was published this spring in Science Advances. In it, researchers trained sample algorithmic systems to automatically decide whether a given rule was being broken. For example, one of these machine-learning programs examined photographs of people to determine whether their outfits violated an office dress code, and another judged whether a cafeteria meal adhered to a school’s standards. Each sample program had two versions, however, with human programmers labeling the training images in a slightly different way in each version. In machine learning, algorithms use such labels during training to figure out how other, similar data should be categorized.
For the dress-code model, one of the rule-breaking conditions was “short shorts or short skirt.” The first version of this model was trained with photographs that the human annotators were asked to describe using terms relevant to the given rule. For instance, they would simply note that a given image contained a “short skirt”—and based on that description, the researchers would then label that photograph as depicting a rule violation.
For the other version of the model, the researchers told the annotators the dress code policy—and then directly asked them to look at the photographs and judge which outfits broke the rules. The images were then labeled accordingly for training.
Although both versions of the automated decision-makers were based on the same rules, they reached different judgments: the versions trained on descriptive data issued harsher verdicts and were more likely to say a given outfit or meal broke the rules than those trained on past human judgments.
“So if you were to repurpose descriptive labels to construct rule violation labels, you would get more rates of predicted violations—and therefore harsher decisions,” says study co-author Aparna Balagopalan, a Ph.D. student at the Massachusetts Institute of Technology.
The discrepancies can be attributed to the human annotators, who labeled the training data differently if they were asked to simply describe an image versus when they were told to judge whether that image broke a rule. For instance, one model in the study was being trained to moderate comments in an online forum. Its training data consisted of text that annotators had labeled either descriptively (by saying whether it contained “negative comments about race, sexual orientation, gender, religion, or other sensitive personal characteristics,” for example) or with a judgment (by saying whether it violated the forum’s rule against such negative comments). The annotators were more likely to describe text as containing negative comments about these topics than they were to say it had violated the rule against such comments—possibly because they felt their annotation would have different consequences under different conditions. Getting a fact wrong is just a matter of describing the world incorrectly, but getting a decision wrong can potentially harm another human, the researchers explain.
The study’s annotators also disagreed about ambiguous descriptive facts. For instance, when making a dress code judgment based on short clothes, the term “short” can obviously be subjective—and such labels influence how a machine-learning system makes its decision. When models learn to infer rule violations depending entirely on the presence or absence of facts, they leave no room for ambiguity or deliberation. When they learn directly from humans, they incorporate the annotators’ human flexibility.
“This is an important warning for a field where datasets are often used without close examination of labeling practices, and [it] underscores the need for caution in automated decision systems—particularly in contexts where compliance with societal rules is essential,” says co-author Marzyeh Ghassemi, a computer scientist at M.I.T. and Balagopalan’s adviser.
The recent study highlights how training data can skew a decision-making algorithm in unexpected ways—in addition to the known problem of biased training data. For example, in a separate study presented at a 2020 conference, researchers found that data used by a predictive policing system in New Delhi, India, was biased against migrant settlements and minority groups and might lead to disproportionately increased surveillance of these communities. “Algorithmic systems basically infer what the next answer would be, given past data. As a result of that, they fundamentally don’t imagine a different future,” says Ali Alkhatib, a researcher in human-computer interaction who formerly worked at the Center for Applied Data Ethics at the University of San Francisco and was not involved in the 2020 paper or the new study. Official records from the past may not reflect today’s values, and that means that turning them into training data makes it difficult to move away from racism and other historical injustices.
Additionally, algorithms can make flawed decisions when they don't account for novel situations outside their training data. This can also harm marginalized people, who are often underrepresented in such datasets. For instance, starting in 2017, some LGBTQ+ YouTubers said they found their videos were hidden or demonetized when their titles included words such as “transgender.” YouTube uses an algorithm to decide which videos violate its content guidelines, and the company (which is owned by Google) said it improved that system to better avoid unintentional filtering in 2017 and subsequently denied that words such as “trans” or “transgender” had triggered its algorithm to restrict videos. “Our system sometimes makes mistakes in understanding context and nuances when it assesses a video’s monetization or Restricted Mode status. That’s why we encourage creators to appeal if they believe we got something wrong,” wrote a Google spokesperson in an e-mail to Scientific American. “When a mistake has been made, we remediate and often conduct root cause analyses to determine what systemic changes are required to increase accuracy.”
Algorithms can also err when they rely on proxies instead of the actual information they are supposed to judge. A 2019 study found that an algorithm widely used in the U.S. for making decisions about enrollment in health care programs assigned white patients higher scores than Black patients with the same health profile—and hence provided white patients with more attention and resources. The algorithm used past health care costs, rather than actual illness, as a proxy for health care needs—and, on average, more money is spent on white patients. “Matching the proxies to what we intend to predict ... is important,” Balagopalan says.
Those making or using automatic decision-makers may have to confront such problems for the foreseeable future. “No matter how much data, no matter how much you control the world, the complexity of the world is too much,” Alkhatib says. A recent report by Human Rights Watch showed how a World Bank–funded poverty relief program that was implemented by the Jordanian government uses a flawed automated allocation algorithm to decide which families receive cash transfers. The algorithm assesses a family’s poverty level based on information such as income, household expenses and employment histories. But the realities of existence are messy, and families with hardships are excluded if they don’t fit the exact criteria: For example, if a family owns a car—often necessary to get to work or to transport water and firewood—it will be less likely to receive aid than an identical family with no car and will be rejected if the vehicle is less than five years old, according to the report. Decision-making algorithms struggle with such real-world nuances, which can lead them to inadvertently cause harm. Jordan’s National Aid Fund, which implements the Takaful program, did not respond to requests for comment by press time.
Researchers are looking into various ways of preventing these problems. “The burden of evidence for why automated decision-making systems are not harmful should be shifted onto the developer rather than the users,” says Angelina Wang, a Ph.D. student at Princeton University who studies algorithmic bias. Researchers and practitioners have asked for more transparency about these algorithms, such as what data they use, how those data were collected, what the intended context of the models’ use is and how the performance of the algorithms should be evaluated.
Some researchers argue that instead of correcting algorithms after their decisions have affected individuals’ lives, people should be given avenues to appeal against an algorithm’s decision. “If I knew that I was being judged by a machine-learning algorithm, I might want to know that the model was trained on judgments for people similar to me in a specific way,” Balagopalan says.
Others have called for stronger regulations to hold algorithm makers accountable for their systems’ outputs. “But accountability is only meaningful when someone has the ability to actually interrogate stuff and has power to resist the algorithms,” Alkhatib says. “It’s really important not to trust that these systems know you better than you know yourself.”
Picture
Member for
1 month 1 week
Real name
이태선
Position
연구원
Bio
[email protected]
세상은 이야기로 만들어져 있습니다. 다만 우리 눈에 그 이야기가 보이지 않을 뿐입니다. 숨겨진 이야기를 찾아내서 함께 공유하겠습니다.
[해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (MDSA R&D)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
사진=Scientific American
기록적인 불볕더위가 계속되는 여름에는 사람처럼 기계도 그늘을 찾는다. 휴대전화, 데이터 센터, 자동차, 비행기를 포함한 많은 기계는 더위가 지속되면 효율성이 떨어지고 성능이 더 빨리 저하된다. 기계는 자체적으로도 열을 발생시켜 주변의 온도를 더욱 뜨겁게 만든다.
완벽하게 효율적인 기계는 없다. 모든 기계는 작동 중에 약간의 내부 마찰이 발생하는데, 이 마찰로 인해 기계가 열을 발산하므로 외부가 더울수록 기계가 더 뜨거워진다.
리튬 이온 배터리를 사용하는 휴대폰 및 이와 유사한 기기는 섭씨 35도 이상의 기후에서 작동할 때 작동이 중지되는데, 이는 과열과 전자기기의 스트레스 증가를 방지하기 위한 것이다.
혁신적인 상변화 유체를 사용하는 냉각 설계는 기계를 시원하게 유지하는 데 도움이 될 수 있지만, 대부분의 열은 결국 공기 중으로 방출된다. 주변 공기가 뜨거울수록 기계가 효율적으로 작동할 수 있는 적정 온도를 유지하기가 더 어려워진다. 또한 기계가 서로 가까이 있을수록 주변에서 더 많은 열이 발생한다.
물질 변형
날씨나 기계에서 방출되는 과도한 열로 인해 온도가 높아지면 기계의 재료가 변형될 수 있다. 이를 이해하려면 온도가 물질 분자에 미치는 영향을 알아야 한다.
온도는 분자가 얼마나 많이 진동하는지를 측정하는 척도다. 따라서 온도가 높을수록 공기, 땅, 기계의 재료에 이르기까지 모든 것을 구성하는 분자가 더 많이 진동한다.
온도가 상승하고 분자가 더 많이 진동하면 분자 사이의 평균 공간이 커지고 물질은 팽창한다. 뜨거운 콘크리트가 팽창하고 수축하여 결국 균열이 생기는 것을 도로에서 쉽게 볼 수 있다. 이러한 현상은 기계에도 발생할 수 있으며 이는 문제의 시작에 불과하다.
여행 지연 및 안전 위험
고온은 자동차 엔진 오일의 성능을 변화시켜 잠재적인 엔진 고장으로 이어질 수 있다. 예를 들어, 폭염으로 인해 기온이 평소보다 16.7℃ 올라가면 일반적인 자동차 엔진 오일의 점도 또는 두께가 3배 정도 낮아진다.
엔진 오일과 같은 유체는 가열될수록 묽어지므로 너무 뜨거워지면 충분히 두꺼운 유막을 형성하지 못해서 엔진 부품에 마모가 증가할 수 있다.
또한 더운 날에는 타이어 내부의 공기가 팽창하고 타이어 압력이 증가하여 마모가 증가하고 미끄러질 위험이 커질 수 있다.
비행기는 극한 온도에서 이륙하도록 설계되지 않았다. 외부가 더워지면 공기가 팽창하기 시작하고 이전보다 더 많은 공간으로 분산되어 공기의 밀도가 낮아진다. 이러한 공기 밀도의 감소는 비행 중 비행기가 지탱할 수 있는 무게를 감소시켜 여행 지연 또는 항공편 취소로 이어질 수 있다.
배터리 성능 저하
일반적으로 휴대전화, 개인용 컴퓨터 및 데이터 센터와 같은 기기에 포함된 전자 장치는 온도 변화에 따라 다르게 반응하는 여러 종류의 재료로 구성되어 있다. 내부 소재들은 모두 좁은 공간에 나란히 배치되어 있어서 온도가 상승하면 각기 다른 재료가 다르게 변형되어 조기 마모 및 고장으로 이어질 수 있다.
자동차와 일반 전자제품의 리튬 이온 배터리는 작업 온도가 높을수록 성능이 더 빨리 저하된다. 온도가 높으면 배터리 내 리튬을 고갈시키는 부식 반응 속도가 빨라지기 때문이다. 이 과정에서 에너지 저장 용량도 줄어든다. 최근 연구에 따르면 전기 자동차는 섭씨 32도의 날씨에 지속해 노출되면 주행 거리가 약 20% 감소할 수 있다고 한다.
데이터를 저장하는 서버로 가득 찬 데이터 센터는 건물 내부를 시원하게 유지하기 위해 상당한 양의 열을 발산한다. 매우 더운 날에는 칩이 과열되지 않도록 팬이 더 열심히 작동한다. 팬만으로는 충분하지 않을 때도 있다.
센터를 시원하게 유지하기 위해 외부에서 들어오는 건조한 공기를 촉촉한 패드에 통과시킨다. 패드의 수분이 공기 중으로 증발하면 열을 흡수하여 공기를 냉각시키는 원리다. 증발 냉각이라고 하는 이 기술은 경제적이고 효과적인 기법의 하나다.
그러나 증발 냉각에는 많은 양의 물이 동원된다. 이는 물이 부족한 지역에서 자원 부족을 야기하고, 이미 자원 발자국을 과도하게 생성하고 있는 데이터 센터에 추가적인 환경 문제를 일으킬 수 있다.
고통받는 에어컨
에어컨이 가장 필요할 때 에어컨은 효과적으로 작동하지 못한다. 더운 날에는 에어컨 압축기가 가정에서 발생하는 열을 외부로 내보내기 위해 더 열심히 작동해야 하므로 전력 소비와 전체 전력 수요가 불균형적으로 증가한다. 텍사스에서는 섭씨 1도 상승할 때마다 전력 수요가 약 4% 증가한다.
더위가 심한 국가에서는 여름철 전력 수요가 무려 50%나 증가하여 전력 부족 또는 정전의 심각한 위협과 함께 온실가스 배출량 증가로 문제가 가중된다.
열 피해를 예방하는 방법
전 세계의 된더위와 온난화는 사람과 기계 모두에게 장단기적으로 심각한 문제를 일으킨다. 다행히도 피해를 최소화하기 위해 할 수 있는 일이 있다.
첫째, 기계를 냉방이 잘 되고 단열이 잘 된 공간이나 직사광선을 피하는 곳에 보관해야 한다.
둘째, 전기 수요가 적은 시간에 에어컨과 같은 고에너지 기기를 사용하거나 전기 자동차를 충전해야 한다. 이렇게 하면 지역 전력 부족 사태를 피하는 데 도움이 될 수 있다.
열 재사용
과학자와 엔지니어들은 기계에서 방출되는 막대한 양의 열을 재활용하는 방법을 개발하고 있다. 한 가지 간단한 예로 데이터 센터에서 발생하는 폐열을 사용하여 물을 가열하는 데 활용 한다.
또한 폐열을 사용하여 흡수식 냉각기와 같은 공조 시스템을 구동시킬 수 있는데, 흡수식 냉각기는 일련의 화학 및 열전달 과정을 통해 열을 에너지로 변환하여 냉각 장치를 지원한다.
두 경우 모두 무언가를 가열하거나 냉각하는 데 필요한 에너지를 낭비되는 열에서 충당한다. 실제로 발전소의 폐열은 주거용 에어컨 수요의 27%를 지원할 수 있으며, 이는 전체 에너지 소비와 탄소 배출을 줄일 수 있는 효과가 있다.
극심한 더위는 현대 생활의 모든 측면에 영향을 미칠 수 있으며, 폭염은 앞으로도 사라지지 않을 것이다. 하지만 낭비되는 열을 활용할 기회는 놓치지 말아야 한다.
Not only people need to stay cool, especially in a summer of record-breaking heat waves. Many machines, including cellphones, data centers, cars and airplanes, become less efficient and degrade more quickly in extreme heat. Machines generate their own heat, too, which can make hot temperatures around them even hotter.
We are engineering researchers who study how machines manage heat and ways to effectively recover and reuse heat that is otherwise wasted. There are several ways extreme heat affects machines.
No machine is perfectly efficient – all machines face some internal friction during operation. This friction causes machines to dissipate some heat, so the hotter it is outside, the hotter the machine will be.
Cellphones and similar devices with lithium ion batteries stop working as well when operating in climates above 95 degrees Farenheit (35 degrees Celsius) – this is to avoid overheating and increased stress on the electronics.
Cooling designs that use innovative phase-changing fluids can help keep machines cool, but in most cases heat is still ultimately dissipated into the air. So, the hotter the air, the harder it is to keep a machine cool enough to function efficiently.
Plus, the closer together machines are, the more dissipated heat there will be in the surrounding area.
DEFORMING MATERIALS Higher temperatures, either from the weather or the excess heat radiated from machinery, can cause materials in machinery to deform. To understand this, consider what temperature means at the molecular level.
At the molecular scale, temperature is a measure of how much molecules are vibrating. So the hotter it is, the more the molecules that make up everything from the air to the ground to materials in machinery vibrate.
As the temperature increases and the molecules vibrate more, the average space between them grows, causing most materials to expand as they heat up. Roads are one place to see this – hot concrete expands, gets constricted and eventually cracks. This phenomenon can happen to machinery, too, and thermal stresses are just the beginning of the problem.
TRAVEL DELAYS AND SAFETY RISKS High temperatures can also change the way oils in your car’s engine behave, leading to potential engine failures. For example, if a heat wave makes it 30 degrees F (16.7 degrees C) hotter than normal, the viscosity – or thickness – of typical car engine oils can change by a factor of three.
Fluids like engine oils become thinner as they heat up, so if it gets too hot, the oil may not be thick enough to properly lubricate and protect engine parts from increased wear and tear.
Additionally, a hot day will cause the air inside your tires to expand and increases the tire pressure, which could increase wear and the risk of skidding.
Airplanes are also not designed to take off at extreme temperatures. As it gets hotter outside, air starts to expand and takes up more space than before, making it thinner or less dense. This reduction in air density decreases the amount of weight the plane can support during flight, which can cause significant travel delays or flight cancellations.
BATTERY DEGRADATION In general, the electronics contained in devices like cellphones, personal computers and data centers consist of many kinds of materials that all respond differently to temperature changes. These materials are all located next to each other in tight spaces. So as the temperature increases, different kinds of materials deform differently, potentially leading to premature wear and failure.
Lithium ion batteries in cars and general electronics degrade faster at higher operating temperatures. This is because higher temperatures increase the rate of reactions within the battery, including corrosion reactions that deplete the lithium in the battery. This process wears down its storage capacity. Recent research shows that electric vehicles can lose about 20% of their range when exposed to sustained 90-degree Farenheit weather.
Data centers, which are buildings full of servers that store data, dissipate significant amounts of heat to keep their components cool. On very hot days, fans must work harder to ensure chips do not overheat. In some cases, powerful fans are not enough to cool the electronics.
To keep the centers cool, incoming dry air from the outside is often first sent through a moist pad. The water from the pad evaporates into the air and absorbs heat, which cools the air. This technique, called evaporative cooling, is usually an economical and effective way to keep chips at a reasonable operating temperature.
However, evaporative cooling can require a significant amount of water. This issue is problematic in regions where water is scarce. Water for cooling can add to the already intense resource footprint associated with data centers.
STRUGGLING AIR CONDITIONERS Air conditioners struggle to perform effectively as it gets hotter outside – just when they’re needed the most. On hot days, air conditioner compressors have to work harder to send the heat from homes outside, which in turn disproportionally increases electricity consumption and overall electricity demand.
For example, in Texas, every increase of 1.8 degrees F (1 degree C) creates a rise of about 4% in electricity demand.
Heat leads to a staggering 50% increase in electricity demand during the summer in hotter countries, posing serious threats of electricity shortages or blackouts, coupled with higher greenhouse gas emissions.
HOW TO PREVENT HEAT DAMAGE Heat waves and warming temperatures around the globe pose significant short- and long-term problems for people and machines alike. Fortunately, there are things you can do to minimize the damage.
First, ensure that your machines are kept in an air-conditioned, well-insulated space or out of direct sunlight.
Second, consider using high-energy devices like air conditioners or charging your electric vehicle during off-peak hours when fewer people are using electricity. This can help avoid local electricity shortages.
REUSING HEAT Scientists and engineers are developing ways to use and recycle the vast amounts of heat dissipated from machines. One simple example is using the waste heat from data centers to heat water.
Waste heat could also drive other kinds of air-conditioning systems, such as absorption chillers, which can actually use heat as energy to support coolers through a series of chemical- and heat-transferring processes.
In either case, the energy needed to heat or cool something comes from heat that is otherwise wasted. In fact, waste heat from power plants could hypothetically support 27% of residential air-conditioning needs, which would reduce overall energy consumption and carbon emissions.
Extreme heat can affect every aspect of modern life, and heat waves aren’t going away in the coming years. However, there are opportunities to harness extreme heat and make it work for us.
This article was originally published on The Conversation. Read the original article.
[해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (MDSA R&D)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
사진=Scientific American
몇 명의 컴퓨터 과학자들이 스파이와 반체제 인사 모두에게 도움이 될 수 있는 암호화 알고리즘이 등장했다. 연구원들은 외부 관찰자가 메시지가 포함되어 있다는 사실을 발견할 수 없도록 완벽한 보안을 유지하면서 실제 텍스트, 이미지 또는 오디오에 메시지를 숨기는 최초의 알고리즘을 개발했다고 전했다. 과학자들은 최근 열린 표현학습 국제 콘퍼런스에서 이 결과를 발표했다.
눈에 잘 띄지 않게 비밀을 숨기는 기술을 스테가노그래피라고 하는데, 이는 메시지 자체는 숨기지만 메시지가 공유되고 있다는 사실은 숨기지 못하는 일반적으로 사용되는 암호화(cryptography)와 구별된다. 디지털 스테가노그래퍼는 정보를 안전하게 숨기기 위해 통상적인 대화와 통계적으로 같은 단어 또는 이미지 문자열에 메시지를 삽입한다. 안타깝게도 사람이 생성한 콘텐츠는 완벽한 보안을 달성할 만큼 예측할 수 없으나 인공지능은 정의된 규칙을 사용하여 텍스트와 이미지를 생성하므로 잠재적으로 완전히 탐지할 수 없는 비밀 메시지를 생성할 수 있다.
옥스퍼드 대학교의 연구원 크리스티안 슈뢰더 드 비트(Christian Schroeder de Witt)와 카네기 멜 대학교의 연구원 사무엘 소코타(Samuel Sokota)와 그의 동료들은 AI 프로그램을 사용하여 비밀 내용이 포함된 해가 없어 보이는 채팅 메시지를 생성해 냈다. 슈뢰더 드 비트는 "이 채팅은 동일한 생성 AI가 만든 다른 커뮤니케이션과 구별할 수 없다"라며 "AI가 생성한 콘텐츠가 있다는 것을 감지할 수 있지만, 비밀 정보를 인코딩했는지 알 수 없다"라고 확신했다.
이러한 위장을 달성하기 위해 연구원들은 비밀 메시지를 채팅에서 전송할 일련의 밈(또는 텍스트)과 최적으로 일치시키는 알고리즘을 개발하여 맥락에 맞는 콘텐츠를 즉각적으로 선택하는 게 가능했다. 이상적인 결합 분포(coupling distribution)를 선택하는 방식, 즉 비밀 메시지와 해가 없는 콘텐츠(예: 고양이 밈)를 최대한 상호의존적이면서 두 콘텐츠의 적절한 분포를 유지하는 방식으로 배합는 방식을 고안해 낸 것이 가장 큰 성과였다. 이 접근은 계산적으로 난도가 높지만, 연구팀은 최근 정보 이론의 발전을 통합하여 계산 효율을 개선했다. 메시지 수신자는 동일한 연산을 반전시켜 비밀 텍스트를 알아낼 수 있다.
연구진은 이 기술이 인간과 유사한 생성 AI가 보편화됨에 따라 상당한 잠재력을 가지게 되었다고 얘기했다. 레이던 대학교의 학습 및 혁신 센터의 개인정보 보호 책임자 조안나 반 데르 메르베(Joanna van der Merwe)도 이에 동의했다. 반 데르 메르베는 "권위주의 정권하에서 정보 환경이 매우 제한적이고 비밀스럽고 억압적이므로 해당 기술을 적용하여 인권 침해를 문서로 만드는 것이 가장 먼저 떠오르는 사용 사례다"고 말했다. 이 기술이 이러한 시나리오의 모든 문제를 극복할 수는 없지만 좋은 도구는 될 수 있다고 그녀는 덧붙였다.
In an advance that could benefit spies and dissidents alike, computer scientists have developed a way to communicate confidential information so discreetly that an adversary couldn't even know secrets were being shared. Researchers say they have created the first-ever algorithm that hides messages in realistic text, images or audio with perfect security: there is no way for an outside observer to discover a message is embedded. The scientists announced their results at the recent International Conference on Learning Representations.
The art of hiding secrets in plain sight is called steganography—distinct from the more commonly used cryptography, which hides the message itself but not the fact that it is being shared. To securely conceal their information, digital steganographers aim to embed messages in strings of words or images that are statistically identical to normal communication. Unfortunately, human-generated content is not predictable enough to achieve this perfect security. Artificial intelligence generates text and images using rules that are better defined, potentially enabling completely undetectable secret messages.
University of Oxford researcher Christian Schroeder de Witt, Carnegie Mellon University researcher Samuel Sokota and their colleagues used an AI program to create innocent-looking chat messages with secret content. To outside observers, the chat is indistinguishable from any other communication made by the same generative AI: “They might detect that there is AI-generated content,” Schroeder de Witt says, “but they would not be able to tell whether you've encoded secret information into it.”
To achieve this camouflage, the researchers developed an algorithm to optimally match a clandestine message with a series of memes (or text) to be sent in the chat, choosing that content on the fly to suit the context. Their big step was the way their algorithm chooses an ideal “coupling distribution” on the spot—a method that matches secret bits with innocuous content (for example, cat memes) in a way that preserves the right distributions of both while making them as interdependent as possible. This approach is computationally quite difficult, but the team incorporated recent information theory advances to find a near-optimal choice quickly. A receiver on the lookout for the message can invert the same operation to uncover the secret text.
The researchers say this technique has significant potential as humanlike generative AI becomes more commonplace. Joanna van der Merwe, privacy and protection lead at Leiden University's Learning and Innovation Center, agrees. “The use case that comes to mind is the documentation of abuses of human rights under authoritarian regimes and where the information environment is highly restricted, secretive and oppressive,” van der Merwe says. The technology doesn't overcome all the challenges in such scenarios, but it's a good tool, she adds: “The more tools in the toolbox, the better.”
[해외 DS] "AI 규제, 지금이 골든타임", 편향·오류·책임 문제 해결 위한 범정부적 노력 필요
Picture
Member for
1 month 1 week
Real name
이시호
Position
연구원
Bio
[email protected]
세상은 다면적입니다. 내공이 쌓인다는 것은 다면성을 두루 볼 수 있다는 뜻이라고 생각하고, 하루하루 내공을 쌓고 있습니다. 쌓아놓은 내공을 여러분과 공유하겠습니다.
입력
수정
[해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (MDSA R&D)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
사진=Scientific American
인공지능은 어디에나 존재하며, 규제 당국에 엄청난 혼란을 안겨줬다. 정부 기관은 AI의 개발과 배포의 어느 시점에 개입해야 할까? 인공지능을 사용하는 거대한 산업이 자신을 통제할 수 있을까? 인공지능 개발 기업들이 애플리케이션의 내부를 들여다볼 수 있도록 허용할까? 인공지능을 지속 가능하게 개발하고, 윤리적으로 테스트하고, 책임감 있게 배포할 수 있을까?
산업 맞춤 권장 사항 필요해
이러한 질문은 한 기관이나 감독 기관에서 해결할 수 있는 문제가 아니다. 인공지능을 사용해서 챗봇을 만들고, 약물-단백질 상호작용을 찾아내며, 자율 주행 차량을 제어할 수 있다. 그리고 각각은 도움이 되는 것만큼이나 해를 끼칠 가능성도 높다. 따라서 모든 기관이 신속하게 협력하여 이러한 애플리케이션의 안전을 보장하기 위한 기관 간 규칙을 확정하고, 동시에 각 기관의 관할권에 속하는 산업에 적용되는 구체적인 권장 사항을 마련해야 한다.
충분한 감독이 없다면 인공지능은 계속해서 편향되고, 잘못된 정보를 제공하고, 오진을 일으키고, 교통사고와 사망사고를 일으킬 것이다.
기후 변화 억제, 잠재적 대유행 바이러스 분석, 단백질 구조 예측, 불법 약물 분류 지원 등 AI의 놀랍고 유익한 용도가 많이 있지만 AI 제품의 결과는 입력된 정보만큼만 우수할 수 있으며, 바로 여기에 많은 규제 문제가 존재한다.
기본적으로 AI는 방대한 양의 데이터에서 패턴이나 유사성을 찾는 컴퓨팅 프로세스다. 질문을 받거나 문제를 해결하라는 지시를 받으면 학습한 패턴이나 유사성을 사용하여 대답한다. 따라서 에드거 앨런 포(Edgar Allan Poe) 스타일의 시를 써달라고 요청할 때, ChatGPT는 "피로와 슬픔에 젖어 생각"에 잠기지 않는다. 지금까지 발표된 모든 포 작품과 포에 대한 비평, 찬사, 패러디에서 스타일을 유추할 수 있기 때문이다. 그리고 이 시스템에는 분명 '고자질하는 심장(양심)'이 없어서 정확히 알 수는 없지만, 겉으로는 학습한 것처럼 보인다.
논란의 소용돌이 속
먼저 저작권 논란이 있다. 현재로서는 어떤 정보가 AI 애플리케이션에 입력되는지, 출처가 어디인지, 얼마나 좋은지, 대표성이 있는지 알 방법이 거의 없다. 현행 미국 규정에 따라 기업은 코드나 학습 자료를 누구에게도 알릴 필요가 없기 때문이다. 그로 인해 보상이나 공로를 인정받지 못한 예술가, 작가, 소프트웨어 엔지니어들은 원본 저작물을 학습 데이터로 무단 사용한 인기 AI 개발 회사를 상대로 소송을 제기하고 있다.
그리고 안전 문제가 있다. AI는 블랙박스 문제를 안고 있는데 개발자들조차도 모델이 학습 데이터를 어떻게 사용하여 의사 결정을 내리는지 잘 모른다. 잘못된 진단을 받으면 의사에게 그 이유를 물어볼 수 있지만 AI에는 물어볼 수가 없다.
공정성에도 이슈가 있다. 주택 관련 대출이 거절되거나 자동 채용 심사에서 탈락하면 AI에 이의를 제기할 수 없다.
유효성은 어떨까? AI 제작자는 제품을 출시하기 전에 통제된 환경에서 테스트하여 올바른 진단을 내리는지 또는 최상의 고객 서비스 결정을 내리는지 확인한다. 그러나 이러한 테스트의 대부분은 실제 세계의 복잡성을 고려하지 못한다.
또한 인공지능이 실제 세상에 나오면 책임소재는 누구에게 있을까? ChatGPT는 임의의 답을 만들어 내고 종종 '환각' 현상을 보였다. DALL-E를 사용하면 프롬프트를 사용하여 이미지를 만들 수 있지만 이미지가 가짜이고 명예를 훼손하면 어떻게 될까? 이 두 제품을 만든 OpenAI가 책임을 져야 할까, 아니면 가짜를 만드는 데 사용한 사람이 책임을 져야 할까? 프라이버시에 대한 심각한 우려도 있다. 프롬프트에 데이터를 입력하면 그 데이터의 소유권은 누구에게 있을까? 해당 사용자를 추적할 수 있을까? 이것은 윤리 문제 중 하나다.
OpenAI의 CEO인 샘 알트먼(Sam Altman)은 의회에서 AI는 본질적으로 위험할 수 있으므로 규제가 필요하다고 말했다. 많은 기술자는 이 모든 문제가 해결될 때까지 ChatGPT보다 더 강력한 신제품 개발을 유예할 것을 요구했다. 이러한 유예는 새로운 것이 아니다. 1970년대에 생물학자들이 분자 생물학과 질병 이해의 토대가 된 DNA 조각을 한 생물체에서 다른 생물체로 옮기는 것을 보류하기 위해 유예를 한 적이 있다. 현대 머신러닝 기술의 토대를 마련한 것으로 널리 알려진 제프리 힌턴(Geofrrey Hinton)도 AI의 성장에 대해 우려하고 있다.
각국의 대응책 현실적으로 기대에 못 미쳐
중국은 블랙박스와 안전 문제에 초점을 맞춰 AI 규제를 시도하고 있지만, 일각에서는 중국의 이러한 노력을 정부 권력을 유지하기 위한 수단으로 보고 있다. 유럽연합은 위험 평가와 안전 우선의 프레임워크를 통해 정부 개입 문제와 마찬가지로 AI 규제에 접근하고 있다. 백악관은 기업과 연구자들이 AI 개발에 어떻게 접근해야 하는지에 대한 청사진을 제시했지만, 과연 이 가이드라인을 준수하는 사람이 있을까?
최근 미국 연방거래위원회(FTC)의 리나 칸(Lina Khan) 위원장은 인터넷 보호에 대한 이전 경험을 바탕으로 FTC가 AI의 소비자 안전과 효능을 감독할 수 있다고 주장했다. 현재 FTC는 ChatGPT의 부정확성을 조사하고 있다. 하지만 이것만으로는 충분하지 않다. 수년 동안 AI는 고객 서비스, 알렉사, 시리 등을 통해 우리 삶의 일부로 자리 잡았다. AI는 의료 제품에도 적용되고 있고, 이미 정치 광고에 사용되어 민주주의에 영향을 미치고 있다. 사법 체계에서 연방 기관의 규제 권한과 씨름하면서 AI는 빠르게 다음이자 아마도 가장 큰 테스트 사례가 되고 있다. 연방 감독을 통해 이 새로운 기술이 안전하고 공정하게 번창할 수 있기를 바란다.
Artificial intelligence is everywhere, and it poses a monumental problem for those who should monitor and regulate it. At what point in development and deployment should government agencies step in? Can the abundant industries that use AI control themselves? Will these companies allow us to peer under the hood of their applications? Can we develop artificial intelligence sustainably, test it ethically and deploy it responsibly?
Such questions cannot fall to a single agency or type of oversight. AI is used one way to create a chatbot, it is used another way to mine the human body for possible drug targets, and it is used yet another way to control a self-driving car. And each has as much potential to harm as it does to help. We recommend that all U.S. agencies come together quickly to finalize cross-agency rules to ensure the safety of these applications; at the same time, they must carve out specific recommendations that apply to the industries that fall under their purview.
Without sufficient oversight, artificial intelligence will continue to be biased, give wrong information, miss medical diagnoses, and cause traffic accidents and fatalities.
There are many remarkable and beneficial uses of AI, including in curbing climate change, understanding pandemic-potential viruses, solving the protein-folding problem and helping identify illicit drugs. But the outcome of an AI product is only as good as its inputs, and this is where much of the regulatory problem lies.
Fundamentally, AI is a computing process that looks for patterns or similarities in enormous amounts of data fed to it. When asked a question or told to solve a problem, the program uses those patterns or similarities to answer. So when you ask a program like ChatGPT to write a poem in the style of Edgar Allan Poe, it doesn't have to ponder weak and weary. It can infer the style from all the available Poe work, as well as Poe criticism, adulation and parody, that it has ever been presented. And although the system does not have a telltale heart, it seemingly learns.
Right now we have little way of knowing what information feeds into an AI application, where it came from, how good it is and if it is representative. Under current U.S. regulations, companies do not have to tell anyone the code or training material they use to build their applications. Artists, writers and software engineers are suing some of the companies behind popular generative AI programs for turning original work into training data without compensating or even acknowledging the human creators of those images, words and code. This is a copyright issue.
Then there is the black box problem—even the developers don't quite know how their products use training data to make decisions. When you get a wrong diagnosis, you can ask your doctor why, but you can't ask AI. This is a safety issue.
If you are turned down for a home loan or not considered for a job that goes through automated screening, you can't appeal to an AI. This is a fairness issue.
Before releasing their products to companies or the public, AI creators test them under controlled circumstances to see whether they give the right diagnosis or make the best customer service decision. But much of this testing doesn't take into account real-world complexities. This is an efficacy issue.
And once artificial intelligence is out in the real world, who is responsible? ChatGPT makes up random answers to things. It hallucinates, so to speak. DALL-E allows us to make images using prompts, but what if the image is fake and libelous? Is OpenAI, the company that made both these products, responsible, or is the person who used it to make the fake? There are also significant concerns about privacy. Once someone enters data into a program, who does it belong to? Can it be traced back to the user? Who owns the information you give to a chatbot to solve the problem at hand? These are among the ethical issues.
The CEO of OpenAI, Sam Altman, has told Congress that AI needs to be regulated because it could be inherently dangerous. A bunch of technologists have called for a moratorium on development of new products more powerful than ChatGPT while all these issues get sorted out (such moratoria are not new—biologists did this in the 1970s to put a hold on moving pieces of DNA from one organism to another, which became the bedrock of molecular biology and understanding disease). Geoffrey Hinton, widely credited as developing the groundwork for modern machine-learning techniques, is also scared about how AI has grown.
China is trying to regulate AI, focusing on the black box and safety issues, but some see the nation's effort as a way to maintain governmental authority. The European Union is approaching AI regulation as it often does matters of governmental intervention: through risk assessment and a framework of safety first. The White House has offered a blueprint of how companies and researchers should approach AI development—but will anyone adhere to its guidelines?
Recently Lina Khan, Federal Trade Commission head, said based on prior work in safeguarding the Internet, the FTC could oversee the consumer safety and efficacy of AI. The agency is now investigating ChatGPT's inaccuracies. But it is not enough. For years AI has been woven into the fabric of our lives through customer service and Alexa and Siri. AI is finding its way into medical products. It's already being used in political ads to influence democracy. As we grapple in the judicial system with the regulatory authority of federal agencies, AI is quickly becoming the next and perhaps greatest test case. We hope that federal oversight allows this new technology to thrive safely and fairly.
Picture
Member for
1 month 1 week
Real name
이시호
Position
연구원
Bio
[email protected]
세상은 다면적입니다. 내공이 쌓인다는 것은 다면성을 두루 볼 수 있다는 뜻이라고 생각하고, 하루하루 내공을 쌓고 있습니다. 쌓아놓은 내공을 여러분과 공유하겠습니다.
[해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (MDSA R&D)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
사진=Scientific American
교육 현장을 위협하는 생성형 AI
자신감 있고 자연스러운 문장을 즉각적으로 생성할 수 있는 ChatGPT는 학생들에게 유용한 커닝 도구다. 사이언티픽 리포트에 발표된 새로운 연구에 따르면, 대학 수준의 숙제나 시험 문제를 줬을 때, 생성형 인공지능이 대학생과 비슷한 점수를 받았다고 한다. AI 콘텐츠와 인간의 작업을 높은 정확도로 구별할 수 있는 도구가 없으므로 교육자들은 교육 과정 구성과 학생을 평가하는 체계를 재고해야 하며, 인간이 스스로 글을 쓰는 방법을 배우지 못하면 무엇을 잃게 될지 생각해야 할 때이다.
뉴욕대학교 아부다비 캠퍼스에서 연구를 위해 8개 학과를 가르치는 32명의 교수로부터 233개의 학생 평가 문제를 수집했다. 그런 다음 해당 질문에 대해 무작위로 선택된 세 가지 학생 답변을 수집하고 ChatGPT에서 세 가지 다른 답변을 생성했다. 연구 상황을 모르는 훈련된 채점자들에게 평가를 맡긴 결과, 32개 수업 중 9개 수업에서 ChatGPT가 학생의 과제와 동등하거나 더 높은 점수를 받았다. 이 연구의 저자인 뉴욕대학교 아부다비의 컴퓨터 과학자 야시르 자키(Yasir Zaki)와 탈랄 라환(Talal Rahwan)은 사이언티픽 아메리칸에 보낸 이메일에서 "현재 버전의 ChatGPT는 거의 30%의 수업에서 학생들과 비슷하거나 심지어 더 우수합니다."라고 전했다. "이 비율은 향후 버전에서 더 높아질 것으로 예상됩니다."
이번 연구 결과는 생성형 AI 모델이 주로 사람이 수행했던 업무에서 탁월한 능력을 발휘할 수 있음을 시사하는 최초의 사례가 아니다. OpenAI에 따르면 ChatGPT를 구동하는 모델인 GPT-3.5와 최신 모델인 GPT-4는 모두 다양한 대학수학능력시험, SAT, GRE의 여러 부문을 인상적인 성적으로 통과할 수 있다고 한다. 또한 GPT-4는 변호사 시험, 법학적성시험(LSAT), 각종 소믈리에 시험에서도 두각을 나타냈다고 회사 측은 평가했다. 외부 연구에서도 비슷한 결과가 나왔는데, 의과대학 입학시험과 아이비리그 기말고사 시험에서 GPT 3.5가 인간 평균 점수를 능가할 수 있다는 실험 결과가 있었다. 이 연구들은 생성형 AI가 교육에 미치는 파괴적인 영향력을 암시한다. 교사와 교육 전문가들은 그들도 이런 상황에 적응해야 한다고 말한다.
베를린 기술경제응용과학대학(HTW 베를린)의 컴퓨터 과학 교수인 데보라 웨버-울프(Debora Weber-Wulff)는 학생들이 ChatGPT로 과제 답을 조작하는 것을 막기 위해 대규모 언어 모델(LLM)에 직접 사용하기로 했다. 그녀는 AI를 통해 시험과 과제 문제를 출제한 다음, AI의 오답을 유도하는 문장 형태로 질문을 수정했다. "ChatGPT로 쉽게 풀 수 없는 문제를 만들고 싶어요."라고 그녀는 강조했다. 이 전략이 완벽한 것은 아니다. 이미 더 발전된 LLM이 존재하며, 업데이트와 파인튜닝을 통해 ChatGPT가 시간이 지남에 따라 프롬프트에 응답하는 방식이 변경될 수 있다. 또한 웨버-울프 교수가 미처 생각하지 못한 적절한 답변을 얻기 위한 특정 요령이 ChatGPT에서 나올 수도 있다. "학생들이 저를 놀라게 하고 그것이 가능하다는 것을 보여줄 수도 있습니다."라고 그녀도 인정했다. "모르죠. 저도 계속 배우고 있죠." 분명한 것은 그녀는 이전보다 더 큰 노력을 기울여 부정행위를 막고 있다는 사실이다. 그리고 이 문제는 단순히 기술에 관한 이야기가 아니다.
근본적인 해결책은 제재가 아니라 개혁
AI 개발자가 부정행위를 발명하지 않았다. AI가 교육에 미치는 영향을 연구하는 펜실베이니아 대학교 와튼 경영대학원의 경영학 부교수 에단 몰릭(Ethan Mollick)은 ChatGPT가 출시되기 전 케냐에서는 수천 명의 사람들이 에세이 작성 서비스를 제공했다고 지적한다. 사람이 에세이를 써주면 비용이 들지만 ChatGPT는 무료다. LLM으로 인해 부정행위를 저지르는 일이 그 어느 때보다 쉬워지고 접근성이 좋아졌다. 그는 수십 년 동안 지속되어 온 문제, 즉 일부 학생들이 학교 과제를 배움의 기회가 아니라 단순히 해치워야 하는 작업으로 여긴다는 점을 꼬집었다.
조지아 주립대학교의 교육 심리학자인 조 마글리아노(Joe Magliano)는 교육의 인센티브 구조가 뒤죽박죽이 되었다고 비판했다. 학생들은 종종 노력이나 이해가 아닌 시험 성적에 따라 보상받는다. 특히 고등 교육은 학생들이 "명백히 열등한 학습 전략을 사용하도록 인센티브를 주었다"라고 마글리아노는 덧붙였다. 문해력과 기술을 연구하는 찰스턴대학의 교육학 교수인 이안 오번(Ian O’Byrne)도 이에 동의했다. "여기서 진짜 위기는 AI랑 연관성이 적습니다."라고 그는 운을 뗐다. "이러한 생성 도구를 통해 교실 안팎에서 실제로 일어나는 일을 거울처럼 들여다볼 수 있게 되었을 뿐입니다."
따라서 교육자들은 학생들의 ChatGPT 사용을 막는 데 초점을 맞출 것이 아니라 학업 부정행위의 근본 원인을 해결하는 데 중점을 두어야 한다고 미시간 주립대학교의 교육 심리학자 쿠이 시에(Kui Xie)는 역설했다. 시에 교수는 부정행위와 표절이 학습에 대한 학생의 태도와 관련이 있다고 진단했다. 학생이 실력을 익히고자 하는 동기가 있다면 부정행위를 할 이유가 없지만 유능해 보이거나, 동료보다 경쟁에서 앞서거나, 단순히 학점을 받는 것이 주된 목표라면 학생은 AI를 포함한 모든 도구를 사용해서 앞서 나가기 위해 부정행위를 저지를 수 있다.
AI 기반 부정행위는 학생의 지식을 평가하기 어렵게 만들 뿐만 아니라 학생들이 스스로 글 쓰는 방법을 배우지 못하게 할 위험도 있다. 글을 잘 쓰는 것은 대부분 직업에서 유용하며 개인의 표현 방식으로서도 가치가 있다. 하지만 글쓰기는 그 자체로 중요한 학습 도구이기도 하다. 인지 연구에 따르면 글쓰기는 사람들이 개념 간의 연결을 형성하고, 통찰력과 이해력을 높이며, 다양한 주제에 걸쳐 기억력과 기억 회상력을 향상하는 데 도움이 된다. 글쓰기와 학습의 상호 연관성을 연구하는 래드포드대학의 심리학자 캐슬린 아놀드(Kathleen Arnold)는 글쓰기의 중요성을 앞과 같이 강조했다. 작문 과제를 ChatGPT에 맡기면 더 나은 작문 실력을 갖추지 못할 뿐만 아니라, 학업 및 지적 성장의 모든 면에서 지장을 받을 수 있다. 아놀드 교수는 이런 상황이 걱정스럽다고 언급했다. 하지만 AI 도구를 위협이 아닌 교육적 기회로 재인식할 가능성도 존재 한다.
AI 도구와 교실의 지혜로운 공생
각급의 교육자들은 경쟁보다 성장을 장려하는 방향으로 수업과 과제를 설계할 수 있으며, 그 과정에서 기술을 활용할 수 있다. 교사는 학생들이 집에서 AI의 도움을 받아 자기 주도적으로 학습한 다음, 수업 시간을 동료와 협력하는 데 사용하는 '플립러닝' 교육 방식을 제안할 수 있다. AI가 풀 수 있는 숙제를 통해 이해도를 확인하는 대신, 프로젝트를 통해 수업 중 지식을 쌓고 입증하는 양질의 교육 환경을 조성할 수 있다.
단계적으로 성적을 폐지하거나 최소화하는 것도 하나의 방법이라고 시에 교수는 주장했다. 교사가 학생의 최종 결과물에 정량적 가치를 부여하는 것이 아니라 개별화되고 과정에 초점을 맞춘 피드백을 제공하면 학생들은 AI를 이용해 부정행위를 하려는 경향이 줄어들 수 있다는 관점이다. 낮은 난도의 과제를 더 자주 출제하는 것도 도움이 될 수 있다. 정성적인 피드백과 대량의 과제를 평가하는 데는 교사의 시간과 노력이 더 많이 요구되지만, 여기서도 생성형 AI가 작업 속도를 높이는 도구로 활용될 수 있다고 시에 교수는 생각했다.
또한 아이디어 형성 과정에서 브레인스토밍 파트너로 ChatGPT를 활용하면 학생들 간 정보 교환에 유용할 수 있다고 오번 교수는 말했다. 교육자는 학생들에게 자신의 목적을 위해 AI 도구를 적용하는 방법을 가르치고, 윤리적 사용에 대한 기대치를 명확히 제시하고, 투명성을 장려함으로써 AI 도구를 적재적소에 사용하는 학생을 길러낼 수 있다. 다른 전략으로는 암기 위주의 평가를 지양하고 분석과 종합을 강화하는 방향으로 전환하는 것 등이 있다. 뉴욕대학교 아부다비 연구 결과에 따르면 ChatGPT는 사실 기반 질문 답변에 가장 능숙했으며, 개념적 프롬프트가 주어졌을 때는 학생의 성적에 크게 뒤처졌다.
마글리아노 교수는 이상적으로 생성형 AI가 계산기나 맞춤법 검사기와 비슷해질 수 있다고 내다봤다. 더 유용하기도 하고 덜 유용하기도 한 도구들일 뿐이다. 문제는 학생들이 이러한 도구를 사용할 때와 사용하지 않을 때를 알 수 있도록 안내하는 것이다.
With its ability to pump out confident, humanlike prose almost instantaneously, ChatGPT is a valuable cheating tool for students who want to outsource their writing assignments. When fed a homework or test question from a college-level course, the generative artificial intelligence program is liable to be graded just as highly, if not better, than a college student, according to a new study published on Thursday in Scientific Reports. With no reliable tools for distinguishing AI content from human work, educators will have to rethink how they structure their courses and assess students—and what humans might lose if we never learn how to write for ourselves.
In the new research, computer scientists and other academics compiled 233 student assessment questions from 32 professors who taught across eight different disciplines at New York University Abu Dhabi. Then they gathered three randomly selected student answers to those questions from each professor and also generated three different answers from ChatGPT. Trained subject graders, blind to the circumstances of the study, assessed all the answers. In nine of the 32 classes, ChatGPT’s text received equivalent or higher marks than the student work. “The current version of ChatGPT is comparable, or even superior, to students in nearly 30 percent of courses,” wrote study authors Yasir Zaki and Talal Rahwan, both computer scientists at N.Y.U. Abu Dhabi, in an e-mail to Scientific American. “We expect that this percentage will only increase with future versions.”
The findings are far from the first to suggest that generative AI models can excel at assessments that are typically reserved for humans. GPT-3.5, the model that powers ChatGPT, and the newer model GPT-4 can both pass various Advanced Placement tests, the SAT and sections of the GRE with impressive grades, according to OpenAI. GPT-4 also purportedly shines at a bar exam, the LSAT and various sommelier tests, per the company’s assessment. Outside research has shown similar results, with trials demonstrating that GPT 3.5 can surpass the human median score on the Medical College Admissions Test and Ivy League final exams. The new study adds to the growing body of work that hints at how disruptive generative AI is set to become in schools—assuming it hasn’t already covertly worked its way into every classroom. In response, teachers and education experts say they need to adapt.
To try to prevent students from fabricating assignment answers with ChatGPT, Debora Weber-Wulff, a computer science professor at the University of Applied Sciences for Engineering and Economics in Berlin (HTW Berlin), has turned to the popular large language model (LLM) herself. She has been preparing for next semester by running exam and homework questions through the AI and then modifying the questions to trip the machine up. “I want to make sure that I have exercises that can’t be simply solved using ChatGPT,” she says. This strategy isn’t foolproof: there are already more-advanced LLMs out there, and updates and fine-tuning mean ChatGPT is liable to change how it responds to prompts over time. There may also be certain tricks to yield suitable answers from ChatGPT that Weber-Wulff hasn’t thought of. “Maybe my students will surprise me and show me that it was possible,” she says. “I don’t know. I will be learning, too.” But what the computer scientist does know is that she’s putting in more effort to try to thwart academic dishonesty now than she was before. And the problem goes far beyond novel technology.
AI developers did not exactly invent cheating. Prior to ChatGPT’s release, thousands of people in Kenya offered essay-writing services to students, notes Ethan Mollick, an associate professor of management at the University of Pennsylvania’s Wharton School of Business, who researches the impacts of AI on education. But getting a person to write your essay costs money, while ChatGPT does not. LLMs have simply made cheating on certain assignments easier and more accessible than ever before, Mollick notes. He highlights a challenge that has been present and growing for decades: some students view school assignments as boxes to check, not opportunities to learn.
The incentive structure of education has become muddled, says Joe Magliano, an educational psychologist at Georgia State University. Students are often rewarded for and reduced to their grades—not their effort or understanding. Higher education, in particular, has “incentivized students to use demonstrably poor learning strategies,” Magliano adds. Ian O’Byrne, an education professor at the College of Charleston, who researches literacy and technology, agrees. “The real big crisis here, it’s less about AI,” he says. “It’s just these generative tools are allowing us to hold up a mirror to what’s really happening in and out of our classrooms.”
The focus for educators thus should not be on preventing students from using ChatGPT but rather on addressing the root causes of academic dishonesty, suggests Kui Xie, an educational psychologist at Michigan State University. Xie studies student motivation, and he chalks up cheating and plagiarism to people’s attitudes toward learning. If a student is motivated to master a skill, there’s no reason to cheat. But if their primary goal is to appear competent, outcompete peers or just get the grade, they’re liable to use any tool they can to come out ahead—AI included.
AI-based cheating not only makes it more difficult to assess students’ knowledge but also threatens to prevent them from learning how to write for themselves. Writing well is a basic human linguistic skill, useful in most professions and valuable as a mode of individual expression. But writing is also a key learning tool in and of itself. Cognitive research has shown that writing helps people build connections between concepts, boosts insight and understanding, and improves memory and recall across a variety of topics, says Kathleen Arnold, a psychologist at Radford University, who studies how writing and learning are interrelated. If a student opts to outsource all their written assignments to ChatGPT, they not only won’t become a better writer—they might also be stunted in their academic and intellectual growth elsewhere. Arnold says it’s a prospect that worries her. But at the same time, it’s an opportunity to rethink teaching and even reconceptualize AI tools as educational opportunities rather than threats to learning.
Educators at every level can design their courses and assignments to better encourage growth over competition, and technology can be a part of that. Teachers could use what Mollick calls “flipped classrooms,” where students would self-direct learning at home—aided in part by AI tutoring tools—and then use class time for working with peers. Instead of proving their grasp of the new material through homework, which could be completed by an AI, they would build on and demonstrate their knowledge through in-class projects.
Phasing out or minimizing grades is another possibility, Xie says. If a teacher’s feedback to students is more individualized and focused on process—rather than just assigning a quantitative value to the final product—students might be less inclined to cheat with AI. More frequent lower-stakes assignments could also help. Qualitative feedback and assessing a larger volume of student work both take more time and effort from teachers, but here again, Xie believes generative AI could be used as a tool to speed up the process.
ChatGPT might also be useful for students in the idea-formation process for any assignment as a brainstorming partner to bounce thoughts off of, O’Byrne says. By teaching students how to apply AI tools for their own benefit, clearly outlining expectations for ethical use and encouraging transparency, educators could end up with tech-savvier pupils who would be less prone to let AI steer the whole ship. Other strategies might include using assessments that avoid a focus on rote memorization and instead shift toward more analysis and synthesis. The N.Y.U. Abu Dhabi study found that ChatGPT was most adept at generating responses to fact-based questions; it fell significantly behind human students’ performance when it was given conceptual prompts.
In an ideal world, our relationship with generative AI might end up similar to the one we have with calculators and spellcheck, Magliano says. All are tools with helpful and less helpful applications. It’s just a matter of ensuring students know when to use them—and when not to.
[email protected]
세상은 이야기로 만들어져 있습니다. 다만 우리 눈에 그 이야기가 보이지 않을 뿐입니다. 숨겨진 이야기를 찾아내서 함께 공유하겠습니다.
입력
수정
[해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (MDSA R&D)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
사진=Scientific American
SF 소설에서는 인공지능이 의식을 갖는 설정을 오랫동안 다뤄왔다. 1968년 영화 '2001 스페이스 오디세이'에서 슈퍼컴퓨터 악당 HAL 9000이 대표적인 예다. 인공지능의 급속한 발전으로 이러한 가능성은 점점 더 현실화하고 있으며, 업계 리더들도 인정하는 분위기다. ChatGPT를 개발한 OpenAI의 수석 과학자 일리야 수츠케버(Ilya Sutskever)는 최첨단 AI 네트워크 중 일부는 "약간 의식이 있을 수 있다"라는 트윗을 올렸다.
많은 연구자는 AI 시스템이 아직 의식의 단계에 이르지 못했다고 말하지만, AI의 발전 속도를 고려하면 의식이 있는지 어떻게 알 수 있을지 고민할 수밖에 없다.
이에 대한 답을 찾기 위해 19명의 신경과학자, 철학자, 컴퓨터 과학자들로 구성된 연구팀이 의식의 존재 여부를 판단할 수 있는 14개 항목의 체크리스트를 고안해 냈다. 이들은 동료 심사를 앞두고 출판 전 논문을 arXiv 저장소에 게시했다. 공동 저자인 캘리포니아 샌프란시스코에 있는 연구 비영리 단체 'AI 안전 센터'의 철학자인 로버트 롱(Robert Long)은 "AI 의식에 대한 심도있는 논의와 실증연구 기반 의논이 실제로 부족한 것 같았기 때문에 이러한 연구를 시작하게 되었습니다"라고 전했다.
연구팀은 AI 시스템이 의식을 갖게 되었는지를 확인하지 못하는 것이 중요한 도덕적 문제를 야기한다고 언급했다. 공동 저자이자 캘리포니아 대학교 어바인 캠퍼스의 신경과학자인 메건 피터스(Megan Peters)는 "무언가가 '의식적'이라고 분류되면 인간으로서 그 개체를 어떻게 대해야 한다고 느끼는지, 도덕적으로 많은 변화가 있습니다"라고 말했다.
롱 교수는 첨단 AI 시스템을 구축하는 회사에서 충분한 노력을 기울이지 않고 있다고 덧붙였다. 그가 아는 한 모델의 의식 수준을 평가하고 의식 있는 AI가 등장할 때 무엇을 해야 할지 대책이 미비하다고 꼬집었다. "주요 AI 연구소 소장들은 AI 의식이나 AI 감성에 대해 궁금하다고 말하지만, 행동으로 옮기진 않았습니다."
롱 교수는 그가 아는 한 모델의 의식 수준을 평가하고 의식 있는 AI가 등장할 경우 무엇을 해야할지 계획을 세우기 위해 첨단 AI 시스템을 구축하는 회사에서 충분한 노력을 기울이지 않고 있다고 덧붙였다. "주요 AI 연구 소장들의 발언을 들어보면 AI 의식이나 AI 감성에 대해 궁금해 한다는 사실에도 불구하고 말입니다."
네이처지는 AI 발전에 앞장서고 있는 주요 기술 기업 두 곳, 마이크로소프트와 구글에 AI 의식에 관해 질문했었다. 마이크로소프트의 대변인은 회사의 AI 개발은 인간의 지능을 복제하는 것이 아니라 책임감 있는 방식으로 인간의 생산성을 지원하는 데 중점을 두고 있다고 전했다. 공개된 ChatGPT의 가장 진보된 버전인 GPT-4의 도입 이후 분명해진 것은 "사회 전체에 혜택을 줄 수 있는 AI의 잠재력을 최대한 끌어내는 방법을 모색하고, 그 기능을 평가하기 위한 새로운 방법론이 필요합니다"라고 강조했다. 한편 구글은 응답하지 않았다.
의식이란 무엇인가?
AI 의식을 연구하는 데 있어 어려운 과제 중 하나는 의식이 있다는 것이 무엇을 의미하는지 정의하는 것이다. 피터스 교수는 연구의 목적성을 위해 의식의 범위를 주관적 경험이라고도 알려진 '현상적 의식'에 초점을 맞췄다. 이는 사람, 동물 또는 AI 시스템(이들 중 하나가 의식이 있는 것으로 밝혀질 경우)이 되는 것이 어떤 것인지에 대한 주관적 경험이다. 주관적 경험은 명시적 및 묵시적 의미를 내포하고 있는데 전자는 인간의 오감과 감정이고 후자는 기억 처리 과정과 같은 의식이 단계로 넘어가기 위한 무의식적인 작용을 일컫는다.
의식을 생물학적으로 설명하는 신경과학 기반 이론도 다양하다. 그러나 어느 것이 '올바른' 이론인지에 대한 합의는 아직 없다. 따라서 저자들은 프레임워크를 만들기 위해 여러 이론을 사용했다. AI 시스템이 해당 이론들의 많은 측면과 일치하는 방식으로 작동하면 의식이 있을 가능성이 더 크다고 판단하는 의사결정 구조다.
그들은 이것이 단순히 행동 유형 검사를 거치는 것보다 더 나은 접근 방식이라고 주장한다. ChatGPT는 사람의 행동 패턴을 모방하는데 놀라울 정도로 능숙해졌기 때문에 의식이 있는지 묻거나 도전적인 질문을 하고 어떻게 반응하는지 보는 것은 신뢰성이 없다.
영국 브라이턴 인근 서식스대학교의 의식과학센터 소장인 신경과학자 아닐 세스(Anil Seth)는 저자들의 이론 중심적 접근 방식은 좋은 방법이라고 동의했다. 그러나 여러 이론을 관통하는 "더 정확하고 잘 검증된 테스트가 필요하다"라고 말했다.
이론 중심 접근
저자들은 의식이 뉴런, 컴퓨터 칩 등 그 구성 요소와 관계없이 시스템이 정보를 처리하는 방식과 관련이 있다고 가정했다. 이러한 접근 방식을 계산기능주의(Computational functionalism)라고 한다. 또한 신경과학 기반 의식 이론도 AI에 적용할 수 있다고 전제했다. 신경과학 기반 의식 이론은 사람과 동물의 뇌를 스캔하는 것과 같은 기술로 연구가 이뤄지는 학문이다.
연구팀은 위의 가정을 바탕으로 6가지 이론을 채택하고 이로부터 14가지 의식 측정 목록을 추출했다. 6개 이론 중 하나인 '전역작업공간' 이론(Global workspace theory)은 인간과 다른 동물이 보고 듣는 것과 같은 인지 작업을 수행하기 위해 모듈이라는 시스템을 사용한다고 가정한다. 이러한 모듈은 독립적으로 작동하지만 병렬로 작업을 처리하고 단일 시스템으로 통합되어 정보를 공유한다. 롱 교수는 특정 AI 시스템이 이 이론에서 파생된 지표에 부합하는지 평가하는 방법은 "시스템의 아키텍처와 정보가 어떻게 흐르는지를 살펴보는 것"이라고 설명했다.
세스 소장은 연구의 투명성에 깊은 인상을 받았다. "매우 사려 깊고 과장되지 않으며 가정이 정말 명확합니다"라고 그는 감탄했다. "일부 가정에 동의하지 않지만 괜찮습니다. 제가 틀렸을 수도 있죠."
저자들은 이 논문이 AI 시스템의 의식을 평가하는 방법에 대한 최종적인 견해가 아니며, 다른 연구자들이 방법론을 개선하는 데 도움을 주기를 바란다고 전했다. 또한 이 항목들을 기존 AI 시스템에 적용하는 것도 이미 가능하며 보고서에서는 ChatGPT와 같은 대규모 언어 모델은 전역작업공간 이론과 관련된 지표 중 일부를 가지고 있음을 발견했다고 밝혔다. 그러나 아직은 강력한 후보가 나타나지 않았다고 얘기했다.
Science fiction has long entertained the idea of artificial intelligence becoming conscious — think of HAL 9000, the supercomputer-turned-villain in the 1968 film 2001: A Space Odyssey. With the rapid progress of artificial intelligence (AI), that possibility is becoming less and less fantastical, and has even been acknowledged by leaders in AI. Last year, for instance, Ilya Sutskever, chief scientist at OpenAI, the company behind the chatbot ChatGPT, tweeted that some of the most cutting-edge AI networks might be “slightly conscious”.
Many researchers say that AI systems aren’t yet at the point of consciousness, but that the pace of AI evolution has got them pondering: how would we know if they were?
To answer this, a group of 19 neuroscientists, philosophers and computer scientists have come up with a checklist of criteria that, if met, would indicate that a system has a high chance of being conscious. They published their provisional guide earlier this week in the arXiv preprint repository1, ahead of peer review. The authors undertook the effort because “it seemed like there was a real dearth of detailed, empirically grounded, thoughtful discussion of AI consciousness,” says co-author Robert Long, a philosopher at the Center for AI Safety, a research non-profit organization in San Francisco, California.
The team says that a failure to identify whether an AI system has become conscious has important moral implications. If something has been labelled ‘conscious’, according to co-author Megan Peters, a neuroscientist at the University of California, Irvine, “that changes a lot about how we as human beings feel that entity should be treated”.
Long adds that, as far as he can tell, not enough effort is being made by the companies building advanced AI systems to evaluate the models for consciousness and make plans for what to do if that happens. “And that’s in spite of the fact that, if you listen to remarks from the heads of leading labs, they do say that AI consciousness or AI sentience is something they wonder about,” he adds.
Nature reached out to two of the major technology firms involved in advancing AI — Microsoft and Google. A spokesperson for Microsoft said that the company’s development of AI is centred on assisting human productivity in a responsible way, rather than replicating human intelligence. What’s clear since the introduction of GPT-4 — the most advanced version of ChatGPT released publicly — “is that new methodologies are required to assess the capabilities of these AI models as we explore how to achieve the full potential of AI to benefit society as a whole”, the spokesperson said. Google did not respond.
WHAT IS CONSCIOUSNESS? One of the challenges in studying consciousness in AI is defining what it means to be conscious. Peters says that for the purposes of the report, the researchers focused on ‘phenomenal consciousness’, otherwise known as the subjective experience. This is the experience of being — what it’s like to be a person, an animal or an AI system (if one of them does turn out to be conscious).
There are many neuroscience-based theories that describe the biological basis of consciousness. But there is no consensus on which is the ‘right’ one. To create their framework, the authors therefore used a range of these theories. The idea is that if an AI system functions in a way that matches aspects of many of these theories, then there is a greater likelihood that it is conscious.
They argue that this is a better approach for assessing consciousness than simply putting a system through a behavioural test — say, asking ChatGPT whether it is conscious, or challenging it and seeing how it responds. That’s because AI systems have become remarkably good at mimicking humans.
The group’s approach, which the authors describe as theory-heavy, is a good way to go, according to neuroscientist Anil Seth, director of the centre for consciousness science at the University of Sussex near Brighton, UK. What it highlights, however, “is that we need more precise, well-tested theories of consciousness”, he says.
A THEORY-HEAVY APPROACH To develop their criteria, the authors assumed that consciousness relates to how systems process information, irrespective of what they are made of — be it neurons, computer chips or something else. This approach is called computational functionalism. They also assumed that neuroscience-based theories of consciousness, which are studied through brain scans and other techniques in humans and animals, can be applied to AI.
On the basis of these assumptions, the team selected six of these theories and extracted from them a list of consciousness indicators. One of them — the global workspace theory — asserts, for example, that humans and other animals use many specialized systems, also called modules, to perform cognitive tasks such as seeing and hearing. These modules work independently, but in parallel, and they share information by integrating into a single system. A person would evaluate whether a particular AI system displays an indicator derived from this theory, Long says, “by looking at the architecture of the system and how the information flows through it”.
Seth is impressed with the transparency of the team’s proposal. “It’s very thoughtful, it’s not bombastic and it makes its assumptions really clear,” he says. “I disagree with some of the assumptions, but that’s totally fine, because I might well be wrong.”
The authors say that the paper is far from a final take on how to assess AI systems for consciousness, and that they want other researchers to help refine their methodology. But it’s already possible to apply the criteria to existing AI systems. The report evaluates, for example, large language models such as ChatGPT, and finds that this type of system arguably has some of the indicators of consciousness associated with global workspace theory. Ultimately, however, the work does not suggest that any existing AI system is a strong candidate for consciousness — at least not yet.
Picture
Member for
1 month 1 week
Real name
이태선
Position
연구원
Bio
[email protected]
세상은 이야기로 만들어져 있습니다. 다만 우리 눈에 그 이야기가 보이지 않을 뿐입니다. 숨겨진 이야기를 찾아내서 함께 공유하겠습니다.
[해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (MDSA R&D)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.
진화의 버튼을 누르는 소셜 미디어/사진=Scientific American
사람들이 온라인 알고리즘과 매일 상호작용하는 것은 다른 사람들로부터 배우는 방식에 영향을 미치며, 사회적 오해, 갈등, 잘못된 정보의 확산 등 부정적인 결과를 초래한다는 사실이 밝혀졌다.
알고리즘은 사용자가 어떤 메시지, 어떤 사람, 어떤 아이디어를 볼지 결정한다. 주로 참여를 지속시키는 정보를 증폭시켜 사람들이 콘텐츠를 계속 클릭하고 플랫폼에 다시 방문하도록 유도한다. 이런 설계의 부작용으로 편향된 정보의 확산이 촉진된다. 편향된 정보는 권위적(Prestigious), 동질적(In-group), 도덕적(Moral), 감성적(Emotional) 정보라는 뜻의 'PRIME'이라고 불린다. 사람들은 PRIME 정보에 민감하게 반응하는 경향성이 있다.
진화 과정에서는 PRIME 정보에서 학습하는 편향은 생존에 매우 유리했다. 권위 있는 개인으로부터 학습하는 것이 효율적이었는데, 권위 있는 사람들은 성공했고 그들의 행동을 모방하면 성공할 가능성이 커지기 때문이다. 또한 도덕 규범을 위반하는 사람들을 제재하면 협력을 유지하는 데 도움이 되기 때문에 도덕규범을 위반하는 사람들을 주의 깊게 살피는 것이 중요했다. 따라서 인간은 PRIME 정보에 대한 집중도가 본능적으로 높다.
위와 같은 사회적 학습 시스템이 자리 잡은 인간 사회에서 만약 알고리즘에 의해 PRIME 정보가 확대 재생산되고 일부 사람들이 자신을 홍보하기 위해 알고리즘을 악용하면 어떻게 될까? 한 마디로 신호 교란이 발생한다. 소셜 미디어에서는 가짜 명성을 쉽게 모방할 수 있으므로 권위는 성공의 올바른 신호가 되지 못하고, 뉴스피드는 부정적이고 도덕성에 민감한 정보로 포화하여 협력보다는 갈등을 유발한다.
사회적 학습은 협력과 문제 해결을 장려하지만 소셜 미디어 알고리즘은 인간의 본능을 지렛대 삼아 참여도를 높이도록 설계되어 있기 때문에 인간의 심리와 알고리즘 증폭의 조합은 역기능으로 이어진다. 이러한 부조화를 기능적 불일치라고 부른다.
왜 중요한가?
기능적 불일치의 주요 부작용 중 하나는 사람들이 현실 세계에 대한 잘못된 인식을 형성하기 시작한다는 것이다. 예를 들어, 알고리즘이 극단적인 정치적 견해를 선택적으로 확산하면, 사람들은 사회 구성원 간의 정치적 견해가 실제보다 더 극명하게 분열되었다고 믿는다. '거짓 양극화'는 더 큰 정치적 갈등의 원인으로 작용할 수 있다.
또한 기능적 불일치는 잘못된 정보의 확산으로 이어질 수 있다. 최근 한 연구 결과에서 정치적 허위 정보를 퍼뜨리는 사람들은 도덕적 분노를 유발하는 정보를 활용하여 사람들이 더 많이 공유하도록 유도한다고 밝혔다. 사실적 묘사와 멀어질수록(수위가 높은 단어를 사용할수록) 더 많은 '좋아요'와 '공유' 그리고 '댓글' 수를 기록했다. 심지어 포스트를 읽지 않았거나 클릭해 보지도 않고 공유하는 행동도 발견됐다.
다른 연구 결과
이 주제에 관한 연구는 아직 걸음마 단계에 있지만, 알고리즘을 매개로 한 사회 학습을 조사하는 새로운 연구들이 등장하고 있다. 5월에 공개된 연구에서는 트위터(현 X)의 알고리즘이 PRIME 정보를 명백하게 확대재생산 한다는 사실이 입증됐다.
이러한 온라인의 영향이 오프라인 양극화로 이어지는지에 대해서는 현재 격렬한 논쟁이 벌어지고 있다. 2020년의 한 실험에서는 메타의 뉴스피드가 양극화를 증가시킨다는 증거가 나왔지만, 메타가 참여한 또 다른 실험에서는 알고리즘에 기반한 뉴스피드 노출로 인해 양극화가 증가했다는 증거는 발견되지 않았다.
사회 학습의 피드백 루프에서 이뤄지는 상호 작용을 완전히 이해하려면 더 많은 연구가 필요하다. 소셜 미디어 기업은 연구에 필요한 데이터 대부분을 보유하고 있으며, 개인정보 보호와 같은 윤리적 문제와 균형을 맞히면서 학계 연구자들에게 데이터 접근 권한을 부여해야 사람들의 사회 인식이 개선될 수 있다.
앞으로의 과제
알고리즘이 편견을 악용하지 않고 올바른 사회 학습을 유도하려면 어떻게 해야 하는가를 질문할 때다. 참여도를 높이는 동시에 PRIME 정보에 페널티를 주는 새로운 알고리즘 설계를 연구해서 사람들의 사회적 인식을 왜곡하지 않는 방안을 고민해야 한다.
People’s daily interactions with online algorithms affect how they learn from others, with negative consequences including social misperceptions, conflict and the spread of misinformation, my colleagues and I have found.
People are increasingly interacting with others in social media environments where algorithms control the flow of social information they see. Algorithms determine in part which messages, which people and which ideas social media users see.
On social media platforms, algorithms are mainly designed to amplify information that sustains engagement, meaning they keep people clicking on content and coming back to the platforms. I’m a social psychologist, and my colleagues and I have found evidence suggesting that a side effect of this design is that algorithms amplify information people are strongly biased to learn from. We call this information “PRIME,” for prestigious, in-group, moral and emotional information.
In our evolutionary past, biases to learn from PRIME information were very advantageous: Learning from prestigious individuals is efficient because these people are successful and their behavior can be copied. Paying attention to people who violate moral norms is important because sanctioning them helps the community maintain cooperation.
But what happens when PRIME information becomes amplified by algorithms and some people exploit algorithm amplification to promote themselves? Prestige becomes a poor signal of success because people can fake prestige on social media. Newsfeeds become oversaturated with negative and moral information so that there is conflict rather than cooperation.
The interaction of human psychology and algorithm amplification leads to dysfunction because social learning supports cooperation and problem-solving, but social media algorithms are designed to increase engagement. We call this mismatch functional misalignment.
WHY IT MATTERS One of the key outcomes of functional misalignment in algorithm-mediated social learning is that people start to form incorrect perceptions of their social world. For example, recent research suggests that when algorithms selectively amplify more extreme political views, people begin to think that their political in-group and out-group are more sharply divided than they really are. Such “false polarization” might be an important source of greater political conflict.
Functional misalignment can also lead to greater spread of misinformation. A recent study suggests that people who are spreading political misinformation leverage moral and emotional information – for example, posts that provoke moral outrage – in order to get people to share it more. When algorithms amplify moral and emotional information, misinformation gets included in the amplification.
WHAT OTHER RESEARCH IS BEING DONE In general, research on this topic is in its infancy, but there are new studies emerging that examine key components of algorithm-mediated social learning. Some studies have demonstrated that social media algorithms clearly amplify PRIME information.
Whether this amplification leads to offline polarization is hotly contested at the moment. A recent experiment found evidence that Meta’s newsfeed increases polarization, but another experiment that involved a collaboration with Meta found no evidence of polarization increasing due to exposure to their algorithmic Facebook newsfeed.
More research is needed to fully understand the outcomes that emerge when humans and algorithms interact in feedback loops of social learning. Social media companies have most of the needed data, and I believe that they should give academic researchers access to it while also balancing ethical concerns such as privacy.
WHAT’S NEXT A key question is what can be done to make algorithms foster accurate human social learning rather than exploit social learning biases. My research team is working on new algorithm designs that increase engagement while also penalizing PRIME information. We argue that this might maintain user activity that social media platforms seek, but also make people’s social perceptions more accurate.
HBP는 뇌의 해부학적 구조를 세밀하게 분석하고 뇌 구조와 기능을 유전자 발현과 연결하는 도구를 개발했다./사진=Scientific American
조각난 그림
HBP를 관통하는 공통적인 문제점으로 파편화를 꼽는다. 프레그낙 교수는 "매우 유용한 응용 프로그램들이 나왔지만, 확장성을 고려한 통합 솔루션은 보이지 않고, 큰 문제를 해결하지도 못했습니다."라고 지적했다.
지난 3년 동안 HBP는 하위 프로젝트들이 개발한 서로 다른 기술을 EBRAINS로 통합하여 파편화되는 것을 극복하려고 노력해 왔다. 6개 플랫폼에 걸친 과제들은 호환할 수 있는 도구와 데이터 표준을 개발하기 시작했으며, 일부 그룹은 특정 과제를 중심으로 재조직되었다. "하지만 아직 해야 할 일이 많이 남아 있습니다."라고 지르사 박사가 말했다. "뉴로로보틱스는 여전히 임상 중심의 분야와 전혀 연결되지 않았습니다."
일부 연구자들은 HBP의 단편적인 과학적 성과가 집중력 부족에서 비롯된 것이라고 비판했다. 항의 서한에 서명한 후 HBP를 떠난 독일 괴팅겐 대학의 이론 신경 물리학자 프레드 볼프(Fred Wolf)는 "10년 이상 지속되는 프로젝트인 만큼 이론적 진전이 이뤄지길 기대했죠."라고 아쉬움을 비쳤다. 프로젝트에 참여하지 않았던 파리의 통합 신경과학 및 인지 센터의 신경과학자 데이비드 한셀(David Hansel)은 HBP가 우선순위를 정하지 않고 협업이 원활하지 못했기 때문에 그 규모를 활용하지 못했고, 공동의 목표를 위해 신경과학 커뮤니티를 단결시키는 데 실패했다고 평가했다. "이 프로젝트에는 해결해야 할 최우선적이고 합리적인 목록이 없었습니다. 구체적이지 못한 포괄적인 '목표'만 있었습니다."
메릴랜드주 베데스다에 있는 미국 국립보건원의 BRAIN 이니셔티브 연구 책임자인 존 응가이(John Ngai)는 가설 중심 과학보다는 자료수집에 중점을 두는 것이 안전했을 거로 생각했다. "과학이 항상 달착륙과 같은 대단한 성과를 내야 하는 것은 아닙니다. 특히 목표를 향한 과정이 불확실한 경우에는 더욱 그렇습니다."
10년의 유산
9월 말, HBP는 기금 지급을 중단할 예정이다. 이 프로젝트에서 나온 일부 과제는 이미 연구비를 확보하여 연구를 계속하고 있지만, HBP에 부분적으로 또는 전체적으로 참여했던 많은 연구자의 미래는 불확실하다.
하지만 아문츠 박사와 다른 연구자들은 HBP의 연구와 EBRAINS 플랫폼이 향후 수년간 유럽 신경과학 연구의 토대가 될 것이라 희망했다. 2018년 1월 HBP는 EBRAINS를 위한 대화형 슈퍼컴퓨팅 도구와 데이터 저장 서비스를 개발하기 위해 5,000만 유로를 지원받았다.
연구원들은 이미 이 플랫폼을 사용하여 뇌가 자극에 어떻게 반응하는지 알아보고 뇌를 모방하는 로봇을 개발하는 등 다양한 연구를 진행하고 있다. 응가이 이사는 HBP가 EBRAINS로 피봇한 덕분에 귀중한 도구가 만들어졌다고 강조했다. 다른 유사 플랫폼도 존재하지만 EBRAINS가 제공하는 규모와 서비스에는 미치지 못한다.
지난 3월, 유럽집행위원회는 EBRAINS를 계속 운영하기 위한 3,800만 유로의 지원금 신청을 거절했지만, HBP와의 협상 끝에 6월에 같은 신청을 재개하여 팀에게 다시 한번 기회를 제공했다. 지원금을 받지 못하면 앞으로 민간 자금과 개별 EU 국가의 재정 지원에 의존해야 한다.
한편, 유럽집행위원회는 본격적인 심의 준비에 착수했다. HBP의 최종 검토는 11월에 시작되어 2024년 1월에 발표될 예정이다. "세계 신경과학계에서 AI의 겨울과 같은 시간을 보내고 싶지 않다면, 우리는 신경과학을 존경받을 만한 수준으로 만들어야 합니다. 이러한 유형의 대규모 프로젝트가 좋은지 아닌지 엄중하게 평가할 필요가 있습니다."라고 프레그낙 교수가 언급했다.
하지만 HBP의 종료가 유럽 신경과학의 종말은 아니라고 EBRAINS의 최고 경영자이자 HBP의 사무총장인 파베우 슈비에보다(Paweł Świeboda)는 힘주어 말했다. 유럽위원회와 회원국은 개인화된 뇌 모델을 사용하여 신약 개발과 뇌 질환 치료법 개선에 박차를 가할 계획이다.
그러나 연구자들은 향후 프로젝트는 HBP의 고질적인 문제들을 피해야 할 것이라고 조언했다. "우리는 처음에 그랬던 것처럼 또 다른 HBP를 하고 싶지 않습니다."라고 오리어리 교수가 토로했다. "메가 프로젝트뿐만 아니라 우선순위가 바로 선 소규모 연구도 지원해야 합니다. 그럼에도 불구하고 이 대규모 프로젝트는 몇 가지 공통된 목표에 집중하는 과학자 커뮤니티를 만들었다고 그는 덧붙였다. "이는 계속 지속될 유산입니다."
NOT THE WHOLE PICTURE The project’s organizers and critics cite a common thread running through the HBP: fragmentation. This is a long-standing issue in neuroscience research. “I see very astute applications, but you don’t see multiscale integration, and you don’t see the big problems being tackled,” says Frégnac.
In its last three years, the HBP has tried to overcome the fragmentation of its interdisciplinary sub-projects by knitting together their technologies into EBRAINS. Initiatives across the HBP’s six platforms started to develop compatible tools and shared data standards, and some groups were re-organized to centre on particular scientific challenges rather than disciplines. “But there is a lot of work to be done,” says Jirsa. “Neurorobotics [still] has zero link to the more clinically driven group.”
For some researchers, the fragmented scientific outcomes of the HBP stem from a lack of focus. “A project that lasts over ten years, I would expect it to produce a conceptual breakthrough,” says Fred Wolf, a theoretical neurophysicist at the University of Göttingen, Germany, who left the HBP after signing the open letter. But that wasn’t the case for the HBP, he says.
David Hansel, a neuroscientist at the Integrative Neuroscience and Cognition Center in Paris, who wasn’t part of the project, says the HBP’s lack of prioritization and limited collaboration meant that it failed to capitalize on its size and to really unite the neuroscience community behind a common goal. “It did not have a list of top and reasonable questions to address. Basically, the ‘goal’ was to understand the brain.”
John Ngai, director of the US National Institutes of Health’s Brain Research Through Advancing Innovative Neurotechnologies (BRAIN) Initiative in Bethesda, Maryland, which focuses on developing tools to catalogue, monitor and measure the brain, thinks that an emphasis on data gathering rather than hypothesis-driven science is defensible. “Big science is not always about moonshots, especially when the steps toward major goals are uncertain.”
THE LEGACY At the end of September, the HBP will cease to give out funds. Although some endeavours that emerged from the project have already secured grants to continue their work, the future is uncertain for many researchers who have worked partly or fully with the HBP.
But Amunts and others hope that the HBP’s work and the EBRAINS platform will be a foundation for European neuroscience for years to come. “Research on the brain requires an understanding of the multilevel and multiscale of the brain,” says Amunts.
In January 2018, the HBP was awarded €50 million, including €25 million from the EU, to develop interactive supercomputing tools and data-storage services for EBRAINS.
Researchers are already using the platform to see how the brain might respond to stimulation, for example, and to develop brain-mimicking robots. Ngai says that the HBP’s pivot to EBRAINS has produced a valuable tool. Similar platforms exist elsewhere, but they lack the scale and services provided by EBRAINS.
In March, the European Commission turned down an application for €38 million to keep EBRAINS running, but reopened the same funding call in June after negotiating with the HBP, giving the team another opportunity to apply. If unsuccessful, the platform will rely on a combination of private funding and financial support from individual EU countries.
Meanwhile, the European Commission is preparing to take stock. The project’s final review will begin in November and is expected to be published in January 2024. “If we don’t want to live the equivalent of the AI winter in global neuroscience, we need to make it respectable. We need really to evaluate if this type of flagship initiative has been good or not,” says Frégnac.
The end of the HBP is not the end of neuroscience in Europe, however, says Paweł Świeboda, chief executive of EBRAINS and director-general of the HBP.
The European Commission and member states are planning the next phase of Europe’s brain-health research, which will focus on using personalized brain models to advance drug discovery and improve treatments for brain disorders.
But researchers say that future projects will need to avoid the struggles that plagued the HBP. “We don’t want to do another HBP as it was in the beginning,” says O’Leary. “We need to support small scale, focused science as well as ambitious integrated projects.”
Ultimately, the mega-project did create communities of scientists focused on some common goals, he says. “That’s an enduring legacy.”
Picture
Member for
1 month 1 week
Real name
이시호
Position
연구원
Bio
[email protected]
세상은 다면적입니다. 내공이 쌓인다는 것은 다면성을 두루 볼 수 있다는 뜻이라고 생각하고, 하루하루 내공을 쌓고 있습니다. 쌓아놓은 내공을 여러분과 공유하겠습니다.