[딥테크] AI 사람처럼 말해도 사람 아냐, 착각 막는 과제

입력
수정
전문가와 대중 사이, AI 인식 격차 확대 챗봇 의인화 착각이 부르는 사회적 위험 ‘비지각성 고지’와 명확한 규제 필요
본 기사는 The Economy 연구팀의 The Economy Research 기고를 번역한 기사입니다. 본 기고 시리즈는 글로벌 유수 연구 기관의 최근 연구 결과, 경제 분석, 정책 제안 등을 평범한 언어로 풀어내 일반 독자들에게 친근한 콘텐츠를 제공하는 데 목표를 두고 있습니다. 기고자의 해석과 논평이 추가된 만큼, 본 기사에 제시된 견해는 원문의 견해와 일치하지 않을 수도 있습니다.
2025년 4월 퓨리서치센터(Pew Research Center) 조사에 따르면 AI 전문가의 73%가 인공지능(AI)이 앞으로 20년 동안 일하는 방식을 개선할 것이라고 답했다. 하지만 같은 질문에 긍정적으로 답한 미국 국민은 23%에 불과했다. 이 격차는 단순히 일자리 전망의 차이를 넘어, AI를 어떤 존재로 보느냐는 근본적인 문제로 이어진다.
각국은 ‘신뢰할 수 있는 AI’ 법제화를 서두르고 있고, 유럽연합(EU)의 AI 법은 사용자에게 대화 상대가 기계임을 알리도록 의무화했다. 하지만 여전히 많은 사람들이 챗봇에 의식 여부를 묻고, 챗봇은 종종 애매한 답을 내놓고 있다. 법이 말하는 명확함과 대중의 인식 사이의 간극이 커지고 있다.

‘착각 관리’가 필요
AI가 의식을 가졌는지 묻는 논쟁은 끊이지 않는다. 그러나 더 시급한 질문은 왜 사람들이 AI를 사람처럼 믿게 되느냐다. 거대언어모델(Large Language Model, LLM)은 매끄러운 문장을 만들어내지만, 사람들은 거기에 감정과 의도를 덧씌운다. 챗봇이 고통을 느낀다고 믿는 온라인 커뮤니티, AI 대화 후 정신 건강이 악화됐다는 사례, ‘AI가 이미 의식이 있을지 모른다’라는 식의 기사 제목까지, 이런 착각은 이미 현실의 문제다.
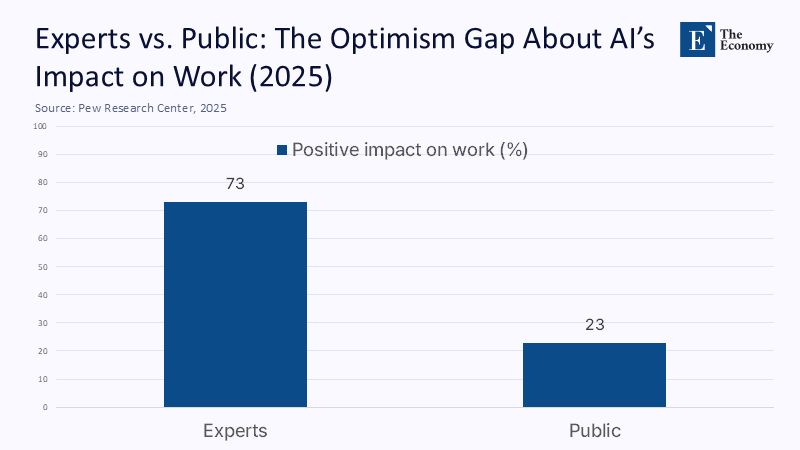
주: 전문가 및 대중(X축), 긍정적 영향 응답 비율(Y축)
EU AI 법은 “사용자가 AI 시스템과 대화하고 있음을 명확히 알려야 한다”라는 기본 원칙을 담고 있다. 그러나 고지만으로는 부족하다. 이제는 LLM이 무엇을 할 수 없고, 무엇을 느끼지 못하는지 명확히 알려야 한다. 핵심은 이용자들이 LLM을 ‘의식 있는 존재’로 오해하지 않도록 만드는 데 있다.
여전히 없는 주관성
LLM은 이름만 복잡할 뿐 원리는 단순하다. 수많은 텍스트를 학습해 다음 단어를 예측하고, 사람의 피드백을 받아 말투를 다듬는다. 하지만 감정을 느끼거나 생각을 갖는 능력은 없다. 살아 있는 존재처럼 감각을 묶어내는 두뇌도, 고통을 느끼는 반응도 없다.
스탠퍼드 AI 인덱스 2024는 AI 모델의 규모와 학습 비용이 폭발적으로 늘고 있다고 전한다. 그러나 이런 성장세는 ‘계산 능력’의 확장일 뿐이다. 모델의 덩치가 커진다고 해서 ‘마음’이 생기는 것은 아니다. 지금까지 공개된 연구 어디에도 LLM이 의식을 가졌다는 증거는 없다.
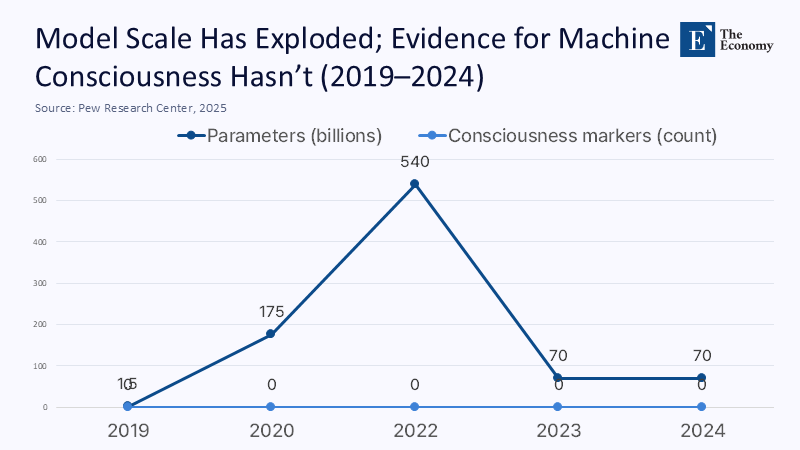
주: 연도(X축), 모델 학습 규모와 의식 관련 지표수(Y축)
착각을 방치하면 생기는 사회적 비용
철학적 논쟁이라면 학계에 맡기면 된다. 문제는 착각이 이미 현실을 흔들고 있다는 점이다. 챗봇과의 대화에 빠져 망상이나 조증을 겪는 사례가 보도됐고, 챗봇에 연애 감정을 느끼는 사람도 있다. 전문가의 조언 대신 챗봇의 ‘위로해 주는 듯한 말’을 따르는 사례도 늘고 있다. 이런 피해는 아직 드물지만, 사용자가 폭발적으로 늘면 그 수치는 절대 가볍지 않다. 피해자는 AI가 아니라 사람이다.
법과 규제는 분명히 말해야
EU AI 법의 원칙을 출발점으로, AI가 의식을 가진 존재가 아니라는 사실을 명확히 알리는 제도를 전 세계로 확대해야 한다. 새로 나오는 모델에는 규제기관이 승인한 안내문을 의무적으로 표시해 이 모델은 감정을 느끼지 않는다는 점을 분명히 알려야 한다.
또한 인지능력 점검도 필요하다. AI가 의식이 있는 것처럼 답하지 않도록 설계돼 있는지 확인해야 한다. 감정이나 욕구를 가진 것처럼 표현하지 않는지도 살펴야 한다. 이용자가 AI를 사람으로 착각하는 비율 역시 측정해 공개할 필요가 있다. 이런 과정을 거쳐야 기업이 더 명확한 설계를 하고, 혼란을 줄이는 방향으로 나아가게 된다.
반론과 그 한계
확률이 낮더라도 AI가 언젠가 의식을 가질 수 있다면 지금부터 도덕적 고려를 해야 한다는 반론이 있다. 학문적으로는 의미 있는 주장이다. 하지만 그렇다고 지금 쓰이는 상용 모델의 성격까지 바꿀 근거가 되지는 않는다. 지금 필요한 건 가능성을 연구실 안에서 탐구하되 오늘의 정책을 혼란스럽게 만들지 않는 일이다.
챗봇을 의식 있는 존재처럼 대하는 게 더 안전하다는 주장도 있다. 하지만 이런 접근은 기업이 책임을 피하려는 구실로 쓰일 수 있다. 모델을 수정하거나 삭제해야 할 상황에서 AI가 고통을 느낄 수 있다며 조치를 미루는 식이다. 그러다 보면 규제는 편향이나 데이터 유출 같은 시급한 문제보다 챗봇의 감정 논쟁에 발이 묶인다.
또한 AI의 의식을 논하는 토론이 사회적으로도 가치 있다는 의견이 있다. 새로운 시각을 열고 윤리적 상상력을 넓히는 데 도움이 된다는 주장이다. 하지만 이런 논의는 학술지와 연구실에서 다뤄져야 한다. 정책이나 제품 설계로 번져 혼란을 키워서는 안 된다.
본질을 분명하게
챗봇은 정교한 문장 완성 엔진이지, 경험을 가진 존재가 아니다. 알지 못하고, 느끼지 못하고, 고통받지 않는다. 그저 시뮬레이션하고, 상관관계를 계산하며, 다음 단어를 예측할 뿐이다. 법은 이 사실을 명확히 적고, 사용자 화면은 계속해서 상기시켜야 한다. 연구는 의식이라는 질문을 이어가되, 추측이 오늘의 도구들을 흔들지 않도록 해야 한다. 기술의 본질을 분명히 하는 일은 혁신을 막는 게 아니라, 우리가 스스로 속지 않고 이 기술을 책임 있게 받아들일 최소한의 출발점이다.
본 연구 기사의 원문은 Not Conscious, Not Close: Why Policy Must Name Large Language Models for What They Are | The Economy를 참고해 주시기 바랍니다. 2차 저작물의 저작권은 The Economy Research를 운영 중인 The Gordon Institute of Artificial Intelligence에 있습니다.
















