[AI Memo] 인공지능을 닮은 검색 엔진

입력
수정
검색 결과가 ‘확증 편향’ 부채질 ‘진실’ 아닌 ‘만족’ 추구로 귀결 해답은 ‘검색 엔진 디자인’에
본 기사는 스위스 인공지능연구소(SIAI)의 SIAI Research Memo 시리즈 기고문을 한국 시장 상황에 맞춰 재구성한 글입니다. 본 시리즈는 최신 기술·경제·정책 이슈에 대해 연구자의 시각을 담아, 일반 독자들에게도 이해하기 쉽게 전달하는 것을 목표로 합니다. 기사에 담긴 견해는 집필자의 개인적 의견이며, SIAI 또는 그 소속 기관의 공식 입장과 일치하지 않을 수 있습니다.
전 세계 인구는 매일 140억 회의 인터넷 검색을 한다. 연간으로 치면 5조 회에 달한다. 학생들에게도 구글 등의 검색 엔진은 과제와 시험 준비를 위한 최후의 의지처나 다름없다. 하지만 이용자의 검색 방식과 검색 엔진의 구조가 결합해 인간의 사고방식을 좁은 틀에 가둔다고 한다. 악의적인 알고리즘이나 의도적인 검열이 아니라 강화 학습(reinforcement learning, 최적의 결과를 얻기 위해 의사 결정을 내리도록 훈련하는 기계 학습 기법)을 닮은 되먹임고리(feedback loop) 때문이라고 한다.

검색 엔진, 이용자 ‘편향성 강화’
검색은 먼저 질문을 입력하고, 순서대로 나오는 결과들을 훑어본 후 그럴듯한 대답을 골라 클릭하는 순서를 따른다. 그러다 어떤 페이지에서 시간을 보내면 검색 엔진은 그것이 유용한 대답이라고 가정한다. 그리고 검색이 거듭될수록 이러한 패턴이 강화된다.
여기에 더해 질문 자체가 특정한 믿음이나 결론을 가정하고 있다면 편향은 더 커진다. 시간이 갈수록 반대되는 결과는 줄고, 이용자의 생각을 확신에 이르게 하는 구체적인 결과들이 더 많이 생성된다. 이는 보통 생각하는 ‘필터 버블’(filter bubble, 알고리즘이 온라인 정보를 개인화하여 사용자를 다양한 관점에서 고립)보다 효과가 더 크다. 인간과 기계가 서로에게 만족스럽다고 느끼는 결과를 알려주는 ‘상호작용’이 발생하기 때문이다. 인공지능(AI) 훈련에 사용하는 ‘인간 피드백을 통한 강화 학습’(reinforcement learning from human feedback, RLHF)과 유사하다.
결과 제시 방법만 바꿔도 ‘영향 커’
최근 연구에 따르면 카페인의 건강에 대한 효과나 휘발유 가격 등 중립적으로 보이는 주제에 대해서도 사용자들이 특정한 결론을 가정해 질문할 때가 있다. 하지만 다양한 관점을 포함하도록 결과를 무작위로 보여주면 이용자들의 의견은 눈에 띄게 달라지는데, 이는 구글은 물론 챗GPT를 통한 검색에서도 동일했다.
서두에 언급한 일일 검색 수를 고려할 때 그중 10~20%만 편향적이라고 해도 수십억 개라는 얘기다. 하지만 90%에 육박하는 점유율을 감안할 때 구글 검색 엔진의 구조에 작은 변화만 도입해도 글로벌 교육에 미치는 영향은 어마어마할 것이다.
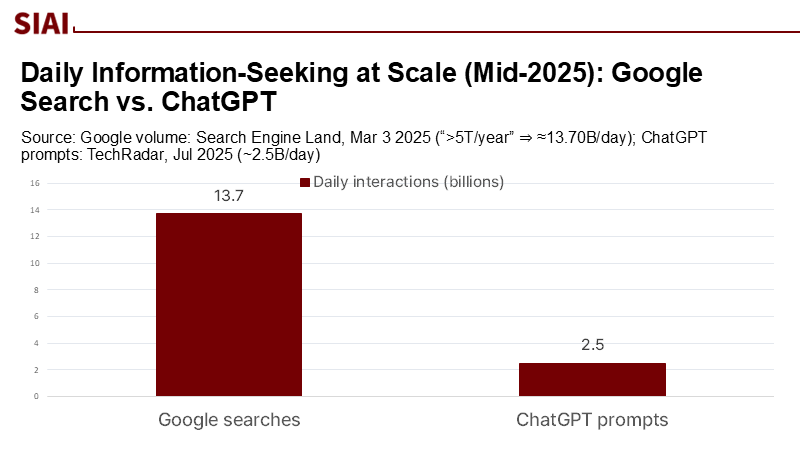
주: 구글 검색(좌측), 챗GPT 지시문(우측)
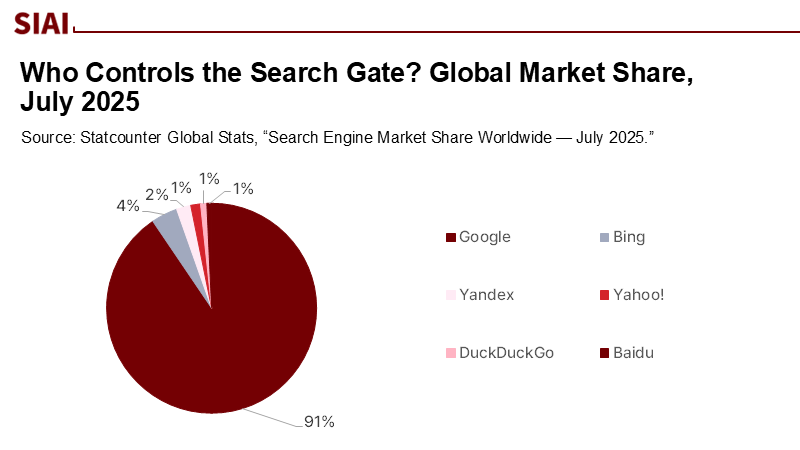
주: 구글, 빙, 얀덱스, 야후, 덕덕고, 바이두(보기 좌→우, 상→하)
‘AI 대화형 검색’ 편향성 ‘더 심해’
편향성은 대형언어모델(large language models, LLMs)의 등장으로 검색이 대화형으로 바뀌며 한층 복잡해졌다. 실험을 통해 보면 AI 기반 검색 엔진을 이용하는 피험자들이 전통적인 구글 검색보다 더욱 편향적인 질문을 하는데, 이는 인간과 AI와의 대화가 상호 작용을 촉진하기 때문이다. 즉, 묻고 대답하는 과정에서 이용자는 마음에 드는 대답이 나올 때까지 질문을 수정해 결국 원하는 결론에 이른다.
하지만 이는 대단한 기술적 결함이 아니다. 검색 결과가 나열되는 순서에 다소의 변화만 줘도 이용자의 검색 패턴과 체류 시간이 바뀐다. 구체적으로 개인화(personalization) 요소를 제거할수록 검색 엔진에 머무는 시간이 줄었는데, 그렇다고 학습효과가 개선된 것은 아니다. 진정한 변화는 개인의 흥미를 저해하지 않으면서 검색 결과를 다양화하는 시스템 구조에 있다.
유용한 방법 중 하나는 경제학에 나오는 도구 변수(instrumental variable, 두 변수 간의 관계에 영향을 미치는 제3의 변수)의 개념을 차용하는 것인데, 이용자가 기존에 가진 믿음과 상관없이 결과에 영향을 미치는 외부 요인을 추가하는 것을 말한다. 이는 다양한 관점을 보여주는 검색 결과를 추가하고, 동의어와 반의어를 번갈아 사용해 검색하며, 해당 카테고리 밖의 검색 결과도 함께 보여주는 방식으로 활용될 수 있다.
흥미 유지하며 다양한 관점 제시해야
중요한 점은 절묘한 균형을 유지하는 것이다. 인위적인 개입이 느껴지거나 의미 없는 결과들이 보여서는 안 된다. 자연스럽게 이용자의 신념 체계 바깥에 있는 결과물이 섞여야 한다.
물론 이러한 시스템 조정이 복잡하고 어렵다는 사실과 도구 변수를 통한 검색 결과 조정이 이용자를 ‘어린애 취급’하는 것과 같다는 비판도 새겨들을 필요는 있다. 하지만 학생들이 검색 결과의 다양성에도 가치를 부여한다는 사실이 실험을 통해 입증된 바 있고, 체류 시간이 짧아진다고 해도 궁극적인 교육의 목표는 검색 시간이 아닌 ‘사실의 이해’임을 기억할 필요가 있다.
검색 자체만 놓고 보면 아직도 검색 엔진이 AI를 압도하고 있고, 학습 도구로서의 유용성도 사라지지 않을 것으로 보인다. 검색 결과의 편향성이 교육 문제에 있어 앞으로도 쟁점이 될 수밖에 없는 이유다. 명심할 것은 인터넷 검색이 ‘자기 위안’이 아닌 ‘진리를 위한 추구’가 돼야 한다는 것이고, 이를 위해 플랫폼들은 클릭 수가 아닌 지식의 획득에 최적화돼야 한다.
본 연구 기사의 원문은 Break the Loop: Why Search Behaves Like Reinforcement Learning—And How to Fix It을 참고해 주시기 바랍니다. 본 기사의 저작권은 스위스 인공지능연구소(SIAI)에 있습니다.
- Previous [딥테크] 관세가 일자리 보호한다고?
- Next 반도체 자립 노리는 中, 핵심 장비 분야서도 존재감 확대
















