[해외 DS] LLM의 혁신을 가져올 두 가지 발견

세상은 다면적입니다. 내공이 쌓인다는 것은 다면성을 두루 볼 수 있다는 뜻이라고 생각하고, 하루하루 내공을 쌓고 있습니다. 쌓아놓은 내공을 여러분과 공유하겠습니다.
입력
수정
[해외DS]는 해외 유수의 데이터 사이언스 전문지들에서 전하는 업계 전문가들의 의견을 담았습니다. 저희 데이터 사이언스 경영 연구소 (GIAI R&D Korea)에서 영어 원문 공개 조건으로 콘텐츠 제휴가 진행 중입니다.

최근 MIT와 Fast.ai 연구팀은 대규모언어모델(이하 LLM)을 더 효과적이고 효율적인 방법으로 훈련할 수 있는 방법론들을 발표했다. MIT에 따르면 LLMs 간의 토론 방식이 사실성과 추론 능력을 향상했고, Fast.ai는 한두 개의 예제만으로도 정확도가 높은 모델링이 가능하다고 전했다.
AI도 혼자 보다 여러명이 더 강하다
MIT 연구팀이 말하는 다중 에이전트의 종류는 두 가지다. 한 종류의 LLM으로부터 만들어진 여러 인스턴스 간의 사회 학습 방법과 여러 종류의 LLM 간의 토론 방식이다. 두 가지 모두 사실성과 추론능력에 긍정적인 영향을 미친 것으로 확인됐다. MMLU 벤치마크(STEM, 인문학, 사회과학 등 57개 과목)뿐만 아니라 여러 영역에서 골고루 높은 성능을 보여줬다.
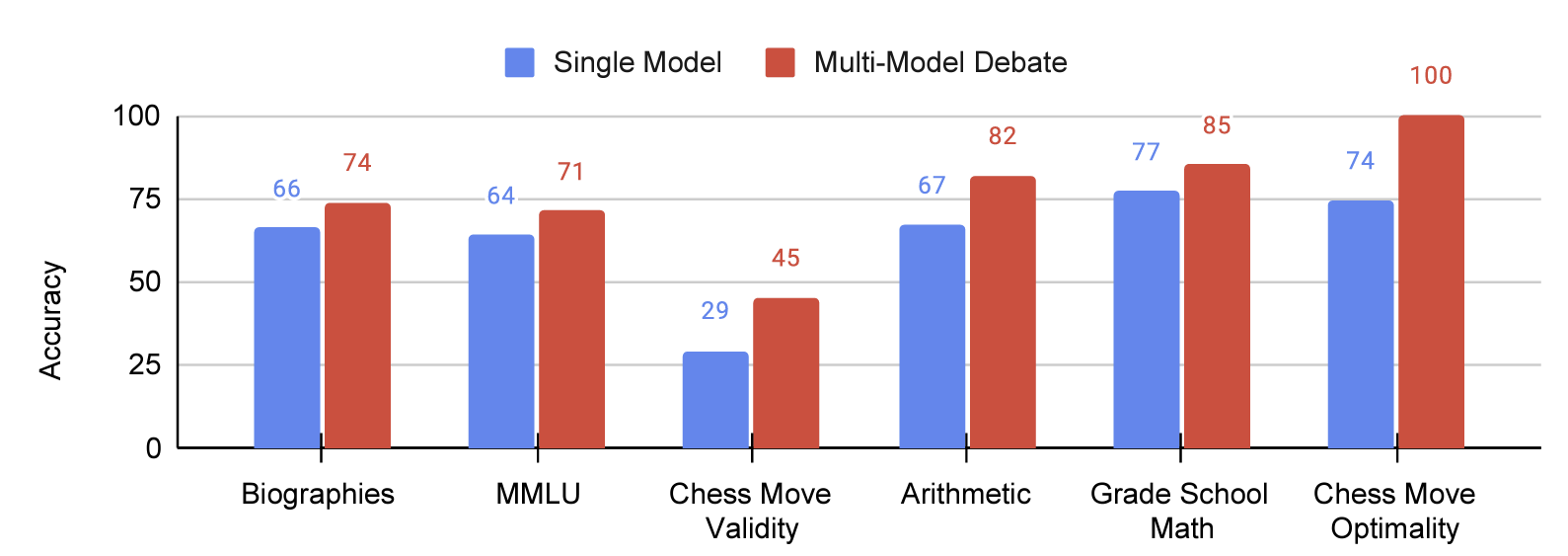
다중 에이전트가 토론하는 방식은 단순하다. 다른 에이전트의 답안을 프롬프트에 붙여 넣고 이를 참고하여 새로운 답안을 작성하라고 요청하는 방식이다. 여기서 답안 작성을 요청하는 횟수(Rounds)도 결과에 영향을 준다고 연구팀은 밝혔다. 더 많은 에이전트로 더 많은 재작성(다른 에이전트의 답안 참고해서)을 요청하면 성능이 더 좋아진다는 논리다. 물론 일정 개수나 횟수가 넘어가면 성능 개선 효과가 줄어들고 계산 비용도 함께 증가하는 한계점도 존재한다. 따라서 적절한 에이전트 수와 재질문 횟수를 정하고 다른 에이전트들의 답을 요약해서 제시하는 등 효율적인 방법들을 모색해야 한다.
에이전트의 수를 늘리고 프롬프트 횟수를 늘리는 방식은 인간의 집단 의사결정 과정과 유사하다. 그리고 이런 친숙한 의사결정 방식이 LLM 예측에도 효력이 있음은 흥미로운 사실이다. 하지만 LLM이 정말 인간처럼 논리의 모순이나 오점을 명확히 파악하고 반성해서 답안을 수정한 것인지 아니면 앵무새처럼 다른 답변을 따라 하는 것인지는 불명확하다. 연구팀은 첫 번째 질문에서 모든 에이전트가 틀렸더라도 다른 에이전트의 답안을 참고한 재질문을 통해 정답을 맞히는 것을 미뤄 보면 단순히 다른 에이전트의 답을 따라하는 것에 그치는 수준은 아니라고 반박한다. 그렇지만 정답을 맞히게 된 원인이 정말 다중 에이전트의 유무에서 결정되는 것인지 아니면 단순히 한 에이전트에 재질문을 함으로써 똑같이 얻을 수 있는지에 대한 의문은 검증이 필요해 보인다. 그리고 정말 LLM이 인간의 사회적 발달 과정과 닮았다면 솔로몬 애쉬의 동조실험에서 인간이 보여준 다수 압력에 굴복하는 모습도 닮지 않았을까? 이에 대해선 연구진은 각 인스턴스의 초기 페르소나를 정하는 것이 도움이 된다고 설명했다. 공감 정도(agreeableness)나 전문분야(과학자, 수학자, 엔지니어 등)를 지정할 수도 있다.
기존 LLM 학습 방식의 관성을 끊을 수 있는 발견
과학 객관식 문제로 LLM의 성능을 평가하는 캐글 경진대회(현지 시각 7월 12일 시작)에서 Fast.ai 연구진은 적은 샘플로도 완전한 학습이 이루어지는 현상을 관측했다. 아래 손실 그래프를 보면 각 epoch(총 3번)의 끝 지점이 명확하게 나뉜다. 이는 보통 코딩 실수로 검증(validation) 단계에서 하지 말아야 학습이 진행되어 검증이 끝날 때 모델의 성능이 갑자기 좋아지는 것처럼 보이는 버그일 가능성이 높다. 하지만 연구진은 곧 실수가 아니라 다른 데이터 세트에서도 반복적으로 나타나는 현상임을 확인했다. "단일 예제에서 거의 완벽하게 학습해야만 설명할 수 있는 그래프입니다"라고 fast.ai 공동 창립자 제러미 하워드(Jeremy Howard)가 강조했다.
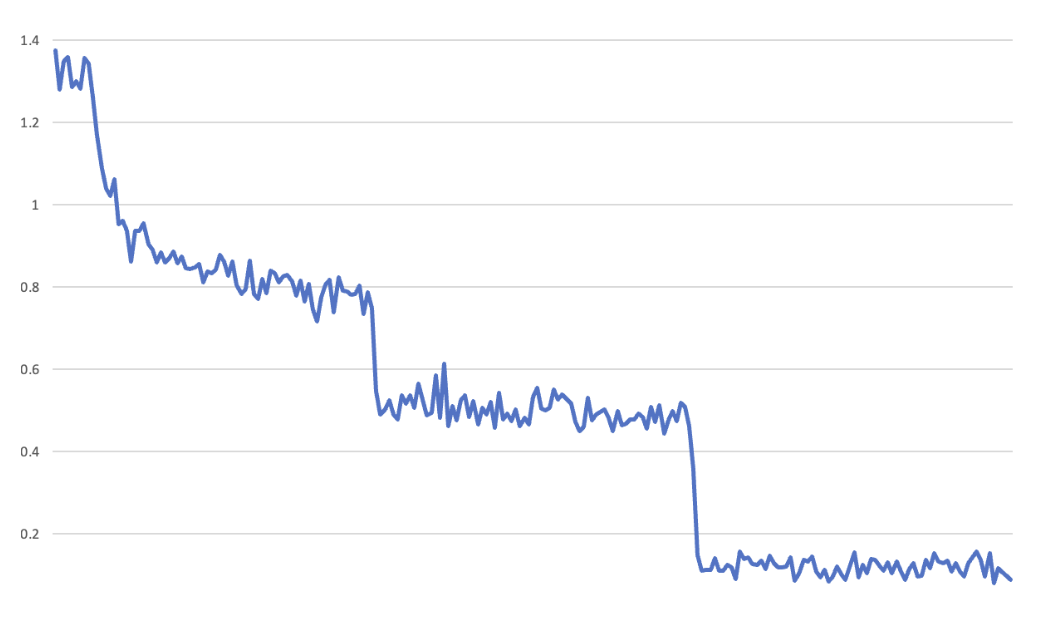
신경망이 단일 예제로 학습할 수 없다는 이론적인 한계가 없고 연구진의 관측이 재현 가능하기 때문에 이들의 주장에 신빙성이 더해지는 이유다. 이 연구 결과는 LLM에서 광범위한 데이터 보강을 통해 여러 epochs에 걸쳐 신경망을 훈련하는 표준 관행이 불필요할 수 있음을 시사한다. 또한 Fast.ai 팀은 모델이 더 적은 수의 간결한 훈련 예제를 통해 더 효과적으로 학습할 수 있으며, 이를 통해 훨씬 적은 자원을 사용하여 더 저렴하고 빠르게 모델을 훈련할 수 있다고 주장했다.
LLM 훈련과 파인튜닝의 새로운 국면
MIT와 fast.ai의 기발한 아이디어를 결합하면 기존의 LLM보다 훨씬 적은 자원으로 높은 성능을 뽑아낼 수 있게 된다. MIT의 다중에이전트 의사결정 방법론은 LLM의 파인튜닝 단계에서 인간의 피드백을 대체할 가능성이 있다. 데이터 간의 관계를 가르치기 위해 수많은 사람이 피드백을 주고 있던 것을 여러 에이전트가 서로 피드백을 주면서 비슷하거나 더 높은 수준의 성능을 끌어올릴 수 있게 될지도 모른다. 한편 fast.ai의 발견처럼 단일 예제로도 온전한 훈련을 마칠 수 있게 된다면 미래엔 자체 LLM 개발 비용이 획기적으로 줄 것이다. 현재 LLM으로 인해 야기된 수많은 문제들(데이터 센터 전력, 환경, 노동)이 점차 해결될 수 있을 것으로 기대된다.
MIT Research: Debating Makes AI Bots Smarter
The 'Society of Minds' approach can reduce AI model hallucinations and improve upon results
A team of MIT researchers found that having multiple AI systems debate answers to questions leads to improved accuracy in responses compared to just using a single AI system.
In a paper titled Improving Factuality and Reasoning in Language Models through Multiagent Debate, the researchers found that leveraging multiple AI systems processes helps correct factual errors and improve logical reasoning.
The MIT scientists, along with Google DeepMind researcher Igor Mordatch, dubbed the process a "Multiagent Society” and found that it reduced hallucinations in generated output. The approach can even be applied to existing black-box models like OpenAI’s ChatGPT.
The process sees various rounds of responses generated and critiqued. The model generates an answer to a given question and then incorporates feedback from other agents to update its own response. The researchers found this process improves the final output as it is akin to the results of a group discussion – with individuals contributing a response to reach a unified conclusion.
The method can also be used to combine different language models – the research pitting ChatGPT against Google Bard. While both models generated incorrect responses to the example prompt, between them, they were able to generate the correct final answer.
Using the Multiagent Society approach, the MIT team was able to achieve superior results on various benchmarks for natural language processing, mathematics and puzzle solving.
For example, on the popular MMLU benchmark, using multiple agents scored the model an accuracy score of 71, while using only a sole agent scored 64.
“Our process enlists a multitude of AI models, each bringing unique insights to tackle a question. Although their initial responses may seem truncated or may contain errors, these models can sharpen and improve their own answers by scrutinizing the responses offered by their counterparts," Yilun Du, an MIT Ph.D. student and the paper’s lead author.
"As these AI models engage in discourse and deliberation, they're better equipped to recognize and rectify issues, enhance their problem-solving abilities, and better verify the precision of their responses.”
You can access the code used in the multiagent project on GitHub.
Is This a Breakthrough in AI Model Training?
Researchers from Fast.ai discover that large language models can learn from limited inputs
Large language models take an age to train – and can be a very costly endeavor. However, researchers from Fast.ai may have discovered a way for models to rapidly memorize examples from very few exposures.
In a technical paper published on the company’s website, the team at Fast.ai found that large language models can remember inputs after seeing them just once.
The team was fine-tuning a large language model on multiple-choice science exam questions and found the model was able to rapidly memorize examples from the dataset after initial exposure to them.
Upon recreating the experiment, the team at Fast.ai was able to back up the theory – potentially necessitating new thinking around model training.
“It’s early days, but the experiments support the hypothesis that the models are able to rapidly remember inputs. This might mean we have to re-think how we train and use large language models,” the Fast.ai team wrote.
How does this work?
Jeremy Howard, the co-founder of Fast.ai, was working with colleague Jonathan Whitaker on a large language model for the Kaggle Science Exam competition. They were training models using a dataset compiled by Radek Osmulski, a senior data scientist at Nvidia.
After three rounds of fine-tuning, they noticed an “unusual” training loss curve - the graphs that show how error rates change during training.
In an explainer thread on X (Twitter), Howard said the pair had noticed similar loss curves before but had always assumed it was due to a bug.
After examining the code – no bug was discovered. Instead, the team at Fast.ai sought other examples of this phenomenon and found “lots of examples of similar training curves.”
Upon re-conducting the tests, the team at fast achieved similar loss curves which co-founder Howard contended “can only be explained by nearly complete memorization occurring from a single example.”
The team at Fast.ai argue that there is “no fundamental law that says that neural networks cannot learn to recognize inputs from a single example. It is just what researchers and practitioners have generally found to be the case in practice.”
The findings could imply that standard practices around training neural networks over many epochs with extensive data augmentation may be unnecessary for large language models.
Instead, the team at Fast.ai propose that models learn better from fewer, more concise training examples – which could allow models to be trained cheaper and faster from using significantly less compute.
세상은 다면적입니다. 내공이 쌓인다는 것은 다면성을 두루 볼 수 있다는 뜻이라고 생각하고, 하루하루 내공을 쌓고 있습니다. 쌓아놓은 내공을 여러분과 공유하겠습니다.
















