中 가성비 AI 모델 '딥시크', 美 AI 패권 흔들리나

입력
수정
中 국내파가 개발한 AI 모델에 시장 지각변동 훨씬 적은 돈으로 챗GPT 필적하는 성능 구현 오픈AI·메타 등, '딥시크發 충격'에 대응 나서
중국의 인공지능(AI) 스타트업 딥시크(DeepSeek)가 전 세계 AI 시장에 지각 변동을 일으키고 있다. 딥시크의 최신 AI 모델 R1이 일부 벤치마크(성능지표)에서 오픈AI의 챗GPT를 앞서는 것으로 알려진 가운데, AI 업계는 오픈AI·구글 등 미국 빅테크가 투자한 개발비의 10분의 1 수준으로 챗GPT에 필적하는 성능을 구현했다는 점에 주목하고 있다. 미국 빅테크들은 딥시크의 가성비 모델에 대해 긍정적인 평가를 내놓으면서도 예상치 못했던 새로운 경쟁자의 등장에 촉각을 곤두세우는 분위기다.
中 과학원 "딥시크, 물리 경시대회서 챗GPT 제쳐"
지난달 31일(현지시각) 중국과학원 물리연구소는 소셜미디어 공식 계정을 통해 물리 경시대회의 AI 테스트 결과를 공개하며 "지난달 17일 장쑤성에서 열린 '톈무(天目)배 이론물리 경시대회'에서 출시된 문제를 AI가 풀도록 한 결과, 딥시크의 최신 모델 R1의 점수가 오픈AI의 GPT-o1을 제쳤다"고 밝혔다. 이번 테스트에는 딥시크의 R1, 오픈AI의 GPT-o1, 앤스로픽의 클로드 소넷 등 3사의 AI 모델이 사용됐는데 딥시크는 140점 만점에 100점으로 1등을 차지했다. 챗GPT는 97점, 클로드 소넷은 71점을 받은 것으로 알려졌다.
3사의 AI 모델에 대한 흥미로운 분석 결과도 공개됐다. 연구소에 따르면 챗GPT는 증명 문제에서 상대적으로 강세를 보였고 답안의 스타일도 인간과 유사했다. 클로드 소넷은 초반 두 문제에서 0점을 받는 실수를 저지르며 예상외로 부진한 성적을 받았다. 딥시크의 경우, 증명 문제에서 강세를 보인 챗GPT와 달리 증명의 의미를 제대로 이해하지 못해 결론을 재서술하는 수준에 그쳤다. 이러한 한계 탓에 딥시크의 성적은 실제 참가자들과 비교하면 전체 3등 수준으로 인간이 받은 최고점 125점과는 격차가 큰 것으로 나타났다.
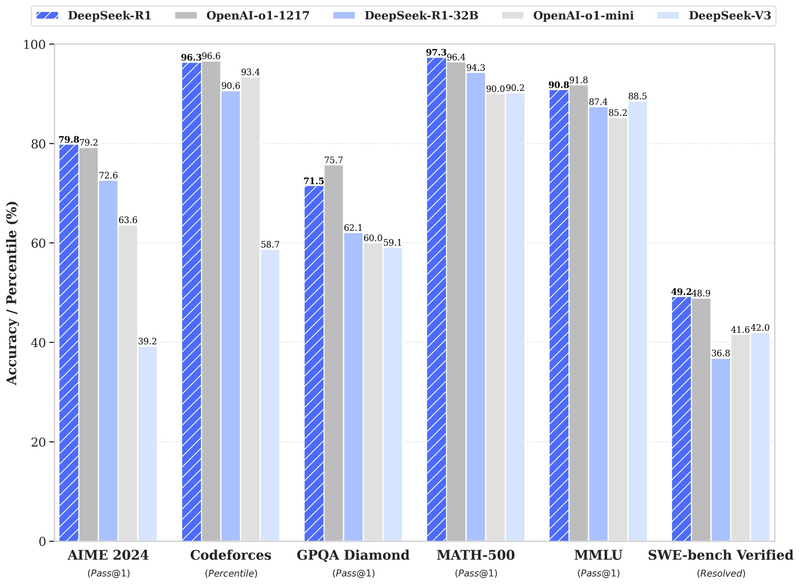
딥시크가 복잡한 문제 해결부터 수학·코딩에 이르기까지 오픈AI·구글 등 최신 AI 모델을 능가한 것으로 알려지자 미국 언론들은 "중국의 젊은 기술 인재를 모여 AI를 집중 연구해 온 작은 기업 딥시크가 미국 주요 빅테크의 아성을 뛰어넘는 놀라운 창의성을 발휘했다"고 평가했다. 기술 전문지 테크크런치에 따르면 R1은 미국 수학경시대회인 AIME 2024 벤치마크 테스트에서 79.8%를 얻어 오픈AI o1(79.2%)을 앞섰다. 코딩 테스트에서도 65.9%의 정확도로 o1(63.4%)을 넘어섰다.

딥시크, 강화학습에 초점 맞춘 창의적 설계에 주목
딥시크는 2023년 5월 중국 항저우에서 설립됐다. 설립자인 1985년생 량원펑은 중국 광둥성 출신으로 공학 분야에서 명문대로 손꼽히는 저장대에서 컴퓨터 공학을 전공했다. 2015년 대학 친구 2명과 함께 '하이-플라이어(High-Flyer)'라는 헤지펀드를 설립하고 컴퓨터 트레이딩에 딥러닝 기법을 이용해 자금을 끌어모았다. 이 펀드의 자산은 80억 달러(약 11조5,000억원) 수준으로 불어났고, 량원펑은 소규모 AI 연구소를 만들어 운영하다 독립적인 회사로 분리해 딥시크를 창업했다.
량원펑의 펀드 하이-플라이어는 2019년부터 거대언어모델(LLM)을 훈련할 수 있는 엔비디아의 그래픽처리장치(GPU) 약 1만 개를 확보해 AI 칩 클러스터를 구축했다. 2023년 11월 딥시크는 첫 번째 오픈소스 AI 모델 '딥시크 코더'를 공개했고 이듬해 5월 한층 진전된 '딥시크-V2'를 출시했다. 이 모델은 강력한 성능과 저렴한 비용으로 크게 주목받으며 중국 내 AI 시장에 가격 전쟁을 촉발했다. 이어 차례로 내놓은 '딥시크-V3'와 '딥시크-R1'은 회사의 이름을 세계에 알리는 계기가 됐다.
특히 딥시크는 주요 빅테크가 개발에 들인 비용보다 훨씬 적은 돈으로 AI 모델을 만들었다고 밝혀 세계를 놀라게 했다. 딥시크에 따르면 V3 개발에 투입한 비용은 557만6,000달러(약 78억8,000만원)인데 이는 메타가 최신 AI 모델 '라마(Llama) 3'를 엔비디아의 고가 칩 'H100'으로 훈련한 비용과 비교해 10분의 1 수준에 불과하다. 특히 최신 추론 모델 R1은 기존 모델의 미세 조정(fine-tuning) 단계를 건너뛰고 강화 학습(reinforcement learning)에 초점을 맞춘 창의적인 설계로 주목받았다.

오픈AI·MS, 자사 데이터 무단 추출 의혹 등 조사
예상치 못한 경쟁자의 등장에 미국의 빅테크들의 반응은 엇갈렸다. 일각에서는 기술이 발전할수록 개발비가 감소하는 '비용 곡선'에 비춰볼 때 딥시크의 성과는 '예상가능하고 정상적인 수준'이라는 평가를 내놨다. 다리오 아모데이 앤트로픽 공동 창업자 겸 최고경영자(CEO)는 지난달 29일 블로그를 통해 "딥시크의 V3 훈련 비용이 1년 전 개발된 자사의 AI 모델보다 약 8배 더 저렴하고 이는 비용 곡선의 추세에 부합한다"며 "이미 주요 빅테크가 실현한 수준의 모델을 한발 늦게 선보인 딥시크를 '혁신'으로 보긴 어렵다"고 지적했다.
반면 IBM AI 연구소의 닉 풀러 부사장은 "딥시크의 AI 모델은 개방형 혁신의 결과물"이라며 "R1이 '전문가 혼합(Mixture of Experts)' 모델을 적용한 점에 주목할 필요가 있다"고 강조했다. 그러면서 "딥시크의 모델이 대형 모델과 달리 특정 목적에 맞게 소형화·전문화될 수 있다는 점에서 AI 시장의 새로운 패러다임을 제시했다"며 "최근 업계에서 주목받는 기술 흐름과 일치한다"고 분석했다. AI 모델의 비용 절감과 고효율성이 강조되면서 기업들은 대형 AI 모델보다 맞춤형 소형 모델을 선호하는 경향이 강해지고 있다는 해석이다.
한편,오픈AI와 마이크로소프트(MS)는 딥시크가 오픈AI의 데이터를 무단으로 수집했다는 의혹을 조사하고 나섰다. 이들은 딥시크가 '증류(Distillation)'라고 불리는 방식으로 오픈AI의 모델을 모방하고 대량의 데이터를 무단 추출해 모델을 개발한 것으로 보고 있다고 로이터는 보도했다. 페이스북의 모회사 메타는 대응 전략을 모색하기 위한 '작전실(war room)'을 꾸린 것으로 전해졌다. 이에 대해 마크 저커버그 메타 CEO는 지난달 29일 실적발표회에서 "모든 사람이 딥시크의 부상에 겁을 먹었지만 메타는 걱정하지 않는다"고 말했다.
















