[딥테크] 항공 탄소 배출 줄이기, 해법은 노선 효율화와 탄소 비용 반영
[딥테크] 항공 탄소 배출 줄이기, 해법은 노선 효율화와 탄소 비용 반영

입력
수정
2000년 이후 항공 탄소 배출 급증, 노선·공역 구조 개선 필요 시장 개방으로 승객당 배출 감소, 총배출량은 증가 감축 핵심 과제는 탄소 비용 반영 및 친환경 연료 확대
본 연구 기사는 유럽 경제 연구소 The Economy의 연구위원(Fellow)들이 작성한 The Economy Review 시리즈 기고문을 한국 시장 상황에 맞춰 재구성한 글입니다. 본 시리즈는 최신 기술-경제-정책 이슈에 대해 연구자의 시각을 담아, 일반 독자들에게도 이해하기 쉽게 전달하는 것을 목표로 합니다. 기사에 담긴 견해는 집필자의 개인적인 의견이며, The Economy 또는 집필자의 소속 기관의 견해와 일치하지 않을 수 있습니다.

1940년 이후 항공 운송에서 발생한 이산화탄소(CO₂)의 절반가량이 2000년 이후에 집중됐다. 항공업계는 차세대 연료와 신형 항공기 등 근본적 해법을 기대하고 있지만, 해당 기술이 실제 운항에 반영되는 속도는 배출 증가 흐름을 따라가지 못하는 수준에 머물러 있다. 따라서 단기간에 감축 효과를 거두기 위해서는 기술 혁신보다 노선 설계와 공역 운영, 시장 구조를 정비하는 접근이 우선돼야 한다.
항공 탄소 배출은 노선 구조가 좌우
2023년 기준 항공 산업은 전 세계 에너지 관련 CO₂ 배출의 약 2.5%(약 9억5,000만 톤)를 차지하며 코로나19 팬데믹 이전의 90% 수준까지 회복했다. 하지만 항공 분야는 다른 산업에 비해 대체 에너지 전환이 쉽지 않아 감축 부담이 크게 나타난다. 항공 수요를 유지하면서 배출량을 줄여야 한다는 점에서 정책 대응의 난도도 높은 편이다.
이 같은 제약 속에서 운항 효율 개선의 중요성이 부각된다. 최근 2,750만 편의 운항 데이터를 분석한 연구에서는 노선과 기종 배치, 탑승률만 효율적으로 조정해도 수송 능력을 유지한 채 전체 탄소 배출의 10.7%를 줄일 수 있다는 결과가 나왔다. 상당한 배출이 비효율적인 노선 구조와 규제 장벽에서 비롯된다는 의미다. 이에 따라 항공 탄소 배출 문제는 운항 구조 전반의 설계 방식에서도 해법을 찾아야 한다는 지적이 나온다.
시장 개방, 효율 개선과 수요 확대 동반
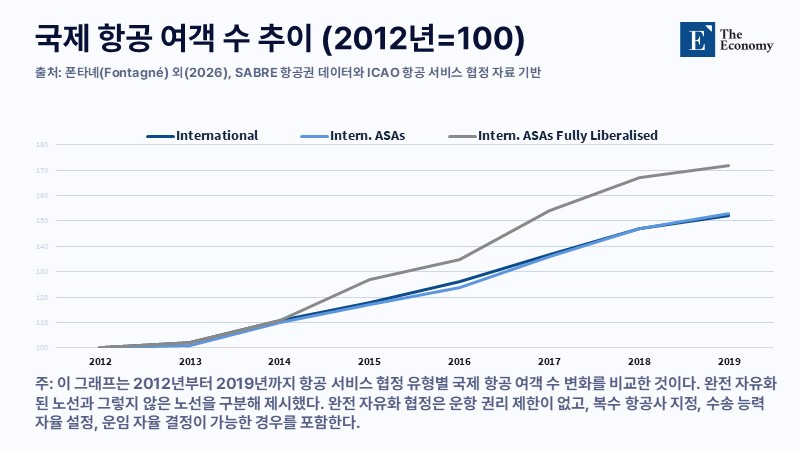
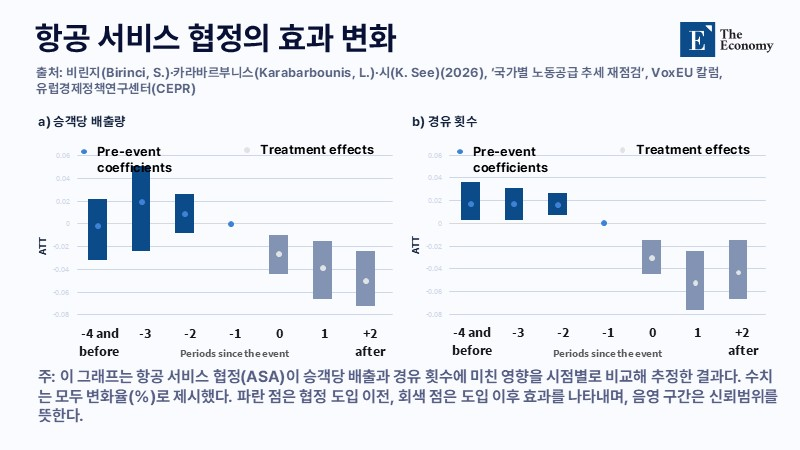
항공 시장 개방은 노선 구조 효율을 높이는 핵심 요인으로 평가된다. 2012년부터 2019년까지 항공 자유화된 국가 간 노선을 보면 직항 확대에 따라 평균 비행시간과 거리가 1.4% 줄었고 경유 횟수도 3.9% 감소했다. 비효율적인 허브 구조가 완화되고 수요가 큰 노선에 최신 기종이 투입되면서 승객 1인당 배출도 약 3% 줄어드는 효과가 확인됐다.
하지만 시장 개방은 수요 확대를 동반한다. 항공 운임이 낮아지고 접근성이 개선되면 항공 이용 자체가 늘어나는 구조다. 유럽경제정책연구센터(CEPR) 분석에 따르면 자유화 이후 승객 수는 4.0% 증가했고 전체 배출은 1.7% 늘었다. 개별 운항의 효율은 개선되지만, 전체 배출 규모는 커지는 구조적 한계가 드러난 셈이다.
규제 장벽이 키운 환경 비용
항공 탄소 배출이 쉽게 줄지 않는 배경에는 비효율을 고착화하는 규제 구조가 있다. 유럽 항공 관제기구(Eurocontrol)에 따르면 2024년 항로 비효율의 절반 이상이 국경 간 규제 장벽과 공역 분리 운영에서 발생했다. 러시아-우크라이나 전쟁 이후 공역 제한으로 우회 비행이 늘면서 전 세계 항공 배출은 약 1% 증가했고, 연간 820만 톤의 탄소가 추가로 배출된 것으로 추산된다.
정치적 판단에 따른 직항 제한, 기존 사업자 중심의 슬롯 배분, 국가별로 나뉜 공역 운영은 항공기를 최단 경로 대신 우회 경로로 유도한다. 이 과정에서 연료 소모와 운항 시간이 늘어나고 비용 부담은 운임 상승으로 이어진다. 동시에 탄소 배출 증가라는 환경 비용도 누적된다.
효율 개선과 탄소 비용 반영 필요
이 같은 구조를 감안하면 항공 배출 감축은 단일 정책으로 해결되기 어렵다. 따라서 시장 개방을 통해 운항 효율을 높이는 동시에 탄소에 비용을 부과하는 장치를 병행해야 한다. 효율 개선과 비용 신호가 함께 작동해야 배출 감소가 실질적인 결과로 이어진다.
유럽연합(EU)은 이러한 방향에서 제도 개편을 추진 중이다. 배출권거래제(EU ETS)에서는 일부 무상으로 배분되던 배출권을 단계적으로 줄이고 2026년부터는 항공사가 필요한 물량을 시장에서 구매하도록 전환할 계획이다. 배출에 따른 비용을 직접 부담하게 만들어 감축 유인을 강화하려는 조치다.
또한 ‘리퓨얼EU 에비에이션(ReFuelEU Aviation)’ 제도를 통해 공항에서 공급되는 항공 연료 가운데 일정 비율 이상을 지속가능항공유(SAF)로 사용하도록 의무화했다. SAF 사용 비중은 2025년 2%에서 출발해 2050년 70%까지 확대하는 것을 목표로 잡았다. 이 같은 조치는 항공사의 연료 선택과 기종 운용, 탑승률 관리 전반에 변화를 요구하는 압박으로 작용한다.
국제 규범 재편과 정책 공조
국제 항공 규범 역시 실효성을 높이는 방향으로 재편이 필요하다. 향후 항공 서비스 협정은 운항 허용 범위를 정하는 수준을 넘어 배출량 보고와 탄소 규제 준수 여부를 시장 접근과 직접 연계하는 구조로 설계돼야 한다. 또한 환경 조항을 형식적으로 포함하는 데 머물지 않고 실제 운항 조건에 반영되도록 하는 장치가 요구된다.
정책 방향도 분명하다. 불필요한 비행 거리를 줄이고 효율이 높은 항공사 중심으로 운항 구조를 재편하며 탄소 비용을 운임과 운영에 반영하는 조치가 함께 추진돼야 한다. 교통·환경 당국과 공항 운영 주체 간 정책 공조가 이뤄질 경우 비효율적 장벽을 해소하고 탄소 비용 신호를 강화하는 기반이 마련된다. 이는 이동 수요를 유지하면서도 배출을 낮추는 산업 구조로의 전환을 가능케 한다.
본 연구 기사의 원문은 To Cut Aviation Emissions, Open the Right Markets and Regulate the Right Costs을 참고해 주시기 바랍니다. 본 기사의 저작권은 The Economy에 있습니다.