[딥테크] 日 외국인 유입 확대와 사회적 수용 격차, 中 커뮤니티 정착 과제 부상
[딥테크] 日 외국인 유입 확대와 사회적 수용 격차, 中 커뮤니티 정착 과제 부상

입력
수정
외국인 증가 속도 못 따라가는 사회적 포용 안보 긴장 속 中 인식 경직 심화 정착 여건 위축 교육 중심의 장기 정착 기반 구축 시급
본 연구 기사는 유럽 경제 연구소 The Economy의 연구위원(Fellow)들이 작성한 The Economy Review 시리즈 기고문을 한국 시장 상황에 맞춰 재구성한 글입니다. 본 시리즈는 최신 기술-경제-정책 이슈에 대해 연구자의 시각을 담아, 일반 독자들에게도 이해하기 쉽게 전달하는 것을 목표로 합니다. 기사에 담긴 견해는 집필자의 개인적인 의견이며, The Economy 또는 집필자의 소속 기관의 견해와 일치하지 않을 수 있습니다.

지난해 말 기준 일본의 외국인 거주자는 400만 명을 넘어섰다. 이 가운데 중국 국적 거주자는 93만 명을 웃돌며 최대 집단 가운데 하나로 자리 잡았다. 노동시장과 교육 영역에서 차지하는 비중도 빠르게 확대되는 흐름이다. 생산 현장에서는 인력 공백을 보완하는 핵심 인력으로 기능하고, 유학생 역시 교육 환경에서 상당한 존재감을 드러낸다.
하지만 이러한 규모 확대가 곧바로 사회 통합으로 이어지진 않는다. 인구 규모 확대는 외국인 유입이 늘었다는 사실은 보여주지만, 사회 내부에서 형성된 심리적·구조적 경계까지 해소됐는지는 설명하지 못한다. 동아시아 특유의 역사 인식과 언어 장벽, 국가 간 긴장이 맞물리며 이러한 간극은 쉽게 완화되지 않는다. 이 때문에 교육의 역할은 단순한 포용을 넘어, 외국인 인구가 사회 안에서 안정적으로 정착할 수 있도록 제도적 기반을 구축하는 것으로 옮겨가고 있다.
커진 존재감, 뒤처진 수용
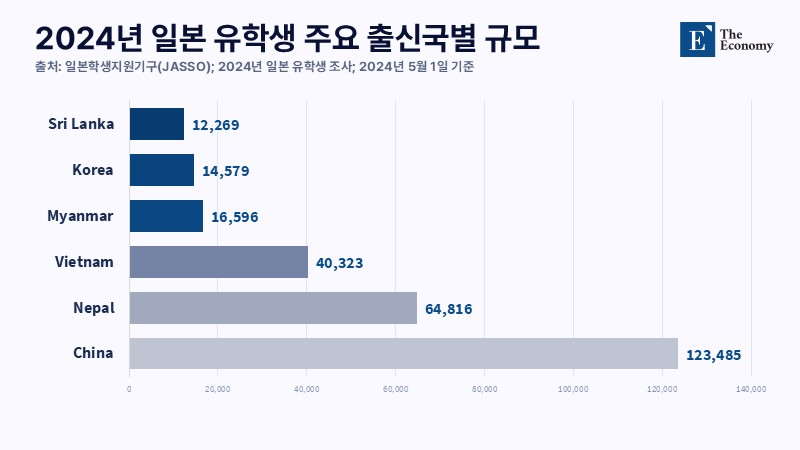
변화의 흐름은 지표에서 확인된다. 지난해 10월 기준 일본의 외국인 노동자는 257만 명으로, 이 가운데 중국인은 43만 명을 웃돌았다. 유학생 역시 비슷한 양상을 보였다. 2024년 외국인 유학생 33만여 명 가운데 약 37%가 중국 출신으로 집계됐다. 노동과 교육 전반에서 중국 커뮤니티의 비중이 빠르게 확대된 결과다.
문제는 존재감 확대가 곧바로 사회적 수용으로 연결되지 않는다는 점이다. 중국인 노동자와 유학생이 인력 부족을 메우고 교육 현장에서 역할이 커졌음에도, 일상 속 관계와 인식은 그만큼 빠르게 변하지 않는다. 일본에서는 외국인 인력을 필요에 따라 받아들이는 수준과 사회 구성원으로 인정하는 수준 사이에 분명한 간극이 존재한다. 이 간극이 지속될 경우 노동과 교육 참여가 늘어나더라도 생활 영역에서는 거리감이 유지될 가능성이 높다.
안보 기조 강화에 흔들리는 사회 인식
외교·안보 환경의 변화는 일본 내 중국인에 대한 인식에도 직접적인 영향을 미치고 있다. 다카이치 사나에 일본 총리는 중국의 강압적 행보를 경고하며 대중 강경 기조를 분명히 했다. 국가 차원에서도 중국을 장기적 위협으로 바라보는 기류가 강화됐다. 그 영향은 일본 사회 전반으로 확산되며 대중 인식에도 반영되는 양상이다.
여론 지표 역시 이를 뒷받침한다. 일본 비영리 싱크탱크 겐론 NPO 조사에서 일본인의 대중 인식은 여전히 부정적 흐름을 보였고, 중국 내에서도 양국 관계를 중요하게 본다는 응답은 크게 줄었다. 이민에 대한 시선도 빠르게 경직되는 분위기다. 일본 바로미터 데이터에 따르면 외국인 노동자 수용 반대 비율은 2022년 35.5%에서 2026년 2월 50%대를 넘어섰다. 경제적 필요보다 안보 인식이 앞서는 흐름이 강화되면서, 중국인 거주자의 정착 여건도 점차 불안정해지는 모습이다.
교육 현장에서 드러난 공백과 제도 한계
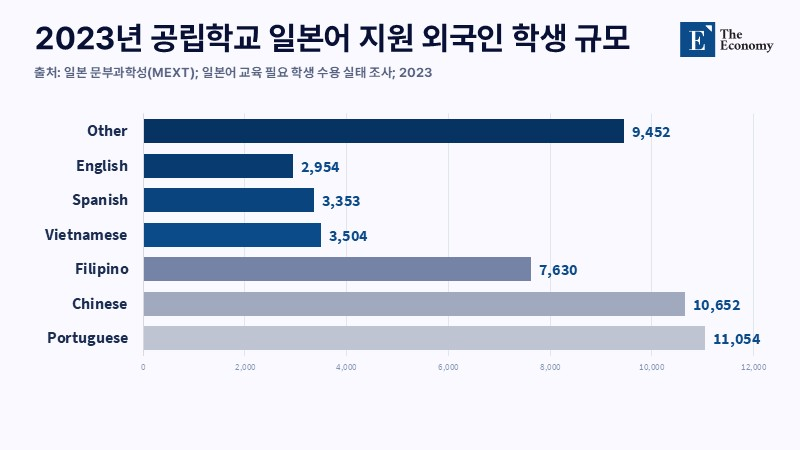
이 같은 구조적 문제는 교육 현장에서 구체적으로 드러난다. 일본 문부과학성에 따르면 2023년 기준 공립학교에서 일본어 교육 지원이 필요한 학생은 7만 명에 달한다. 언어 문제는 수업 참여와 학교 생활은 물론 이후 정착 과정 전반에 영향을 미친다. 그러나 이를 뒷받침할 지원 체계는 충분히 구축되지 않은 상태다. 2021년 조사에서는 학교에 다니지 않는 것으로 확인된 외국인 아동과, 취학 여부를 파악하기 어려운 사례가 적지 않은 것으로 나타났다.
제도적 한계도 분명하다. 경제협력개발기구(OECD)는 일본이 외국인 아동에게 의무교육을 적용하지 않는 점을 주요 과제로 지적했다. 사회 통합을 강조하면서도 교육 참여를 개인 선택에 맡겨 둔 구조다. 여기에 주거와 금융, 취업 과정에서의 제약까지 겹치면서 교육 경험이 생활 전반으로 이어지지 못하는 흐름이 나타난다.
감정을 배제한 제도 중심 전환
향후 정책은 단기간의 감정적 화해를 기대하는 접근에서 벗어날 필요가 있다. 지정학적 긴장이 이어지는 상황에서도 흔들리지 않는 운영 체계를 마련하는 것이 현실적이다. 이에 따라 일본어 교육은 보충 수업 수준을 넘어 장기 프로그램 중심으로 재편해야 하며, 교육 현장에는 이중언어 인력을 배치해 의사소통 공백을 줄여야 한다. 유학생 정책 역시 구성원으로서의 지위를 반영하는 방향으로 정비가 필요하다. 교육이 민족주의 흐름 자체를 바꾸기는 어렵다. 그러나 제도 운영의 기준을 지키는 역할은 수행 가능하다. 따라서 국가 간 관계가 경색되더라도 국내 거주자에 대한 처우는 일관되게 유지돼야 한다. 판단 기준은 일시적인 여론이 아니라 제도의 안정성과 지속성에 달려 있다.
외국인 인구 확대와 사회적 수용 사이의 간극은 일본 사회가 풀어야 할 구조적 과제로 남는다. 이 간극을 방치할 경우 인적 이동은 늘어나는데도 사회 내부의 거리는 더 벌어지는 흐름이 이어질 가능성이 크다. 그 결과 노동시장과 교육, 지역사회 전반에서 갈등과 비효율이 누적되고, 그 비용은 일본 사회 전체로 확산될 수밖에 없다.
본 연구 기사의 원문은 The Chinese Community in Japan and the Myth of Fast Integration을 참고해 주시기 바랍니다. 본 기사의 저작권은 The Economy에 있습니다.