딥시크 무력화하는 엔비디아 괴물 칩, 하드웨어 체급으로 성능 압도
딥시크 무력화하는 엔비디아 괴물 칩, 하드웨어 체급으로 성능 압도

입력
수정
GB300 NVL72 플랫폼, 최고의 AI 학습 성능 초저정밀 연산으로 훈련·추론 동시 가속 저지연·긴 컨텍스트 워크로드 등 에이전틱 AI 인프라 강화
엔비디아가 차세대 인공지능(AI) 인프라 플랫폼 ‘블랙웰 울트라(Blackwell Ultra)’를 앞세워 에이전틱(자율형) AI 추론 시장 공략에 속도를 내고 있다. 최근 전 세계 AI 시장을 뒤흔든 중국 딥시크(DeepSeek)의 공습에도 불구하고, 이를 구동하는 하드웨어 패권은 여전히 엔비디아의 손에 있음이 데이터로 증명됐다. 성능과 가성비를 앞세운 오픈소스 모델이 확산될수록 역설적으로 엔비디아의 최첨단 인프라에 대한 의존도만 더욱 심화되는 모습이다.
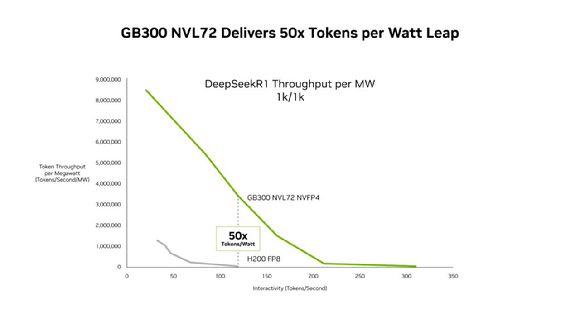
토큰당 비용 최대 35배 절감, MW당 처리량 50배 향상
23일(이하 현지시간) 엔비디아에 따르면 블랙웰 울트라 기반의 'GB300 NVL72'는 기존 '호퍼(Hopper)' 플랫폼 대비 메가와트(MW)당 처리량을 최대 50배 끌어올렸고, 저지연 환경에서는 100만 토큰(AI 모델의 입출력 단위)당 비용을 최대 35분의 1 수준으로 낮췄다. 에이전틱 AI는 코드 생성, 자율형 작업 수행 등 여러 단계를 거치는 구조로, 긴 컨텍스트와 낮은 지연 시간이 핵심이다.
엔비디아는 블랙웰 울트라로 긴 컨텍스트 워크로드(컴퓨터 시스템이 처리해야 하는 작업의 양이나 부하)에서도 비용 경쟁력을 강화했다. 엔비디아는 최대 12만8,000토큰 입력과 8,000토큰 출력을 처리하는 코딩 어시스턴트 기준을 예로 들며, GB300 NVL72는 이전 세대인 GB200 NVL72보다 토큰당 비용을 최대 1.5배 낮췄다고 설명했다.
이번 성능 개선은 하드웨어와 소프트웨어 전반의 병행 최적화에서 비롯됐다. 엔비디아는 그래픽처리장치(GPU) 커널을 저지연 환경에 맞게 재설계해 연산 효율을 높였고, NV링크(NVLink) 기반의 대역폭 확장을 통해 GPU 간 직접 메모리 접근을 강화했다. 여기에 이전 커널이 완전히 종료되기 전 다음 작업을 선제적으로 준비하는 구조를 적용해 유휴 시간을 최소화했다.
벤치마크 전 부문 ‘최고 성능’
실제 대형모델시스템조직(LMSYS)이 21일 공개한 벤치마크 결과에 따르면, 512개의 블랙웰 울트라 GPU로 구성된 GB300 NVL72 시스템은 라마 3.1 405B 사전 훈련 벤치마크를 64.6분 만에 완료했다. 이는 이전 라운드에서 GB200 NVL72 시스템이 FP8 정밀도로 수행한 결과 대비 1.9배가량 빠른 속도다. 또한 실시간 응답 속도를 결정짓는 지연시간 부문에서 1.58배의 개선을 이뤄내며 에이전트 AI 시대의 핵심 병기임을 입증했다.
특히 블랙웰 울트라 GPU는 NVFP4 기준 최대 15페타플롭스(petaFLOPS)의 처리량을 제공하는데, 이는 동일 GPU의 FP8 대비 3배 수준이다. 이론적 수치뿐 아니라 실제 훈련, 워크로드에서도 성능 향상이 확인됐다는 점이 특징이다. 엔비디아는 최근 NVFP4 훈련 레시피를 공개해 모델 개발자들이 더 높은 속도와 비용 효율로 AI를 학습할 수 있도록 지원하고 있다.
추론 영역에서도 NVFP4 전환 효과가 두드러졌다. 전문가 혼합(Mixture-of-Experts, MoE) 구조를 채택한 6,710억 매개변수 모델 딥시크-R1(DeepSeek-R1)의 경우, FP8에서 NVFP4로 전환 시 동일 상호작용 수준에서 토큰 처리량이 크게 향상됐다. 더 높은 토큰 속도 구간에서도 처리량이 유지·확대되며 사용자 응답 지연을 줄이는 데 기여했다. 엔비디아는 NVFP4 양자화 모델이 MLPerf 추론(Inference) 벤치마크의 엄격한 정확도 요건을 충족했다고 밝혔다. 제출 모델에는 딥시크-R1, 라마 3.1 8B·405B, 라마 2 70B 등이 포함됐다.
이번 결과에서 더욱 주목할 부분은 소프트웨어 보정 기술인 다중 토큰 예측(Multi-Token Prediction, MTP)을 적용하지 않고도 높은 성능을 구현했다는 점이다. 기존 GB200의 경우 MTP를 적용해야만 성능이 169.1 TPS(Transaction Per Second)까지 상승했지만, GB300은 별도의 보정 기법 없이도 226.2 TPS를 기록하며 하드웨어 자체의 설계 완성도를 과시했다. 업계에서는 이를 GB300에 탑재된 메모리 대역폭 확장과 연산 엔진 최적화가 이룬 결과로 풀이한다. 특히 긴 문맥을 처리할 때 발생하는 비디오램(VRAM) 부하를 해결하기 위해 프롬프트 처리(프리필)와 토큰 생성(디코드) 단계를 분리하는 PD 디스애그리게이션(Disaggregation) 기술을 통합함으로써 처리 효율을 극대화했다.

MS·코어위브·OCI 이미 도입, 엔비디아 분기 매출 시장예상 상회 전망
이 같은 개선은 실제 서비스 환경에서 체감 성능으로 이어지고 있다. 코어위브의 엔지니어링 총괄부사장 첸 골드버그(Chen Goldberg)는 “긴 컨텍스트 처리 능력과 토큰 효율성은 AI 프로덕션 환경의 핵심 요소”라며 “GB300은 대규모 워크로드에서도 예측 가능한 성능과 비용 효율을 제공한다”고 평가했다.
다만 극한의 성능을 위해서는 대규모 냉각 시스템이 필요하다. GB300 NVL72의 극단적인 전력 밀도는 전통적인 공랭식 설계로는 감당할 수 없을 만큼 높은 열 부하를 유발한다. 모건스탠리의 가치 평가 모델에 따르면, GB300가 이 같은 고열 환경에 대응하기 위해 설계된 수랭식 냉각 하드웨어의 총 자재비(BOM)만 5만 달러(약 7,200만원)에 달한다.
모건스탠리는 랙 내부 구조를 18개의 컴퓨트 트레이와 9개의 스위치 트레이로 가정하고 냉각 비용을 세부적으로 산출했다. 각 컴퓨트 트레이는 약 6.2킬로와트(kW)의 열을 배출하며 이를 감당하는 냉각 구성요소의 비용은 트레이당 2,260달러(약 327만원), 전체 컴퓨트 측 냉각비는 4만680달러(약 5,880만원)로 추산됐다. 스위치 트레이 냉각 비용은 트레이당 1,020달러(약 147만원), 전체 9,180달러(약 1,330만원)로 계산됐다. 특히 CPU와 GPU 칩에 직접 장착되는 고성능 콜드플레이트(cold plate)가 자재비에서 가장 큰 비중을 차지하는 것으로 나타났다.
그러나 높은 유지 비용에도 불구하고 기업들의 반응은 공격적이다. 이미 마이크로소프트(MS), 코어위브(CoreWeave), 오라클 클라우드 인프라스트럭처(OCI) 등 주요 클라우드 사업자들은 GB300 NVL72를 에이전틱 코딩 및 대화형 AI 서비스 환경에 앞다퉈 적용하고 있다. 이에 월가에서는 엔비디아의 하드웨어 고도화가 분기 매출을 크게 견인할 것으로 보고 있다. JP모건은 23일 보고서에서 엔비디아가 오는 25일 발표할 2026회계연도 4분기(11월~1월) 실적이 시장 예상치(656억 달러·약 94조5,000억원)를 상회할 가능성이 높다고 분석했다.
JP모건이 추정한 4분기 블랙웰 및 블랙웰 울트라 랙 출하량은 1만2,000대로, 전 분기 1만 대에서 20% 증가한 수준이다. JP모건은 2026회계연도 전체 랙 출하량도 2만7,000대에 이를 것으로 내다봤다. 여기엔 제품 믹스 개선도 실적 레버리지 요인으로 작용했다. GB300 랙은 GB200 대비 평균 판매 가격(ASP)이 20~30% 높아 매출 확대 효과가 발생한다는 설명이다. JP모건은 2027회계연도 1분기(2~4월) 매출 가이던스도 740억~750억 달러(약 107조~108조원) 범위에서 제시될 가능성이 있다고 봤다. 이 역시 시장 컨센서스(723억 달러·약 104조원)를 웃도는 수준이다.
현시점 수요는 여전히 공급을 크게 상회하고 있다. 미국 클라우드 업체들은 AI 연산 자원 부족을 지속적으로 언급하고 있으며, 일부 GPU 클라우드 인스턴스의 현물 가격 상승은 수급 불균형 심화를 여실히 반영한다. 특히 AI 소프트웨어 발전은 연산 수요를 폭증시키며 고성능 칩에 대한 의존도를 더욱 높이고 있다. 빅테크업계 안팎에서는 딥시크와 같은 거대 모델의 확산이 오히려 엔비디아의 칩 수요를 자극하는 ‘역설적 수혜’를 낳고 있다는 분석도 나온다.















