[AI MEMO] AI 저작권 공방, 데이터 출처 입증이 핵심
[AI MEMO] AI 저작권 공방, 데이터 출처 입증이 핵심

입력
수정
AI 학습 데이터 사용 논란, 합의로 일단락 저작권 소송 쟁점, 데이터 출처 확인 기업 대응 과제, 기록 정비·계약 체계 구축
본 기사는 스위스 인공지능연구소(SIAI)의 SIAI Research Memo 시리즈 기고문을 한국 시장 상황에 맞춰 재구성한 글입니다. 본 시리즈는 최신 기술·경제·정책 이슈에 대해 연구자의 시각을 담아, 일반 독자들에게도 이해하기 쉽게 전달하는 것을 목표로 합니다. 기사에 담긴 견해는 집필자의 개인적 의견이며, SIAI 또는 그 소속 기관의 공식 입장과 일치하지 않을 수 있습니다.

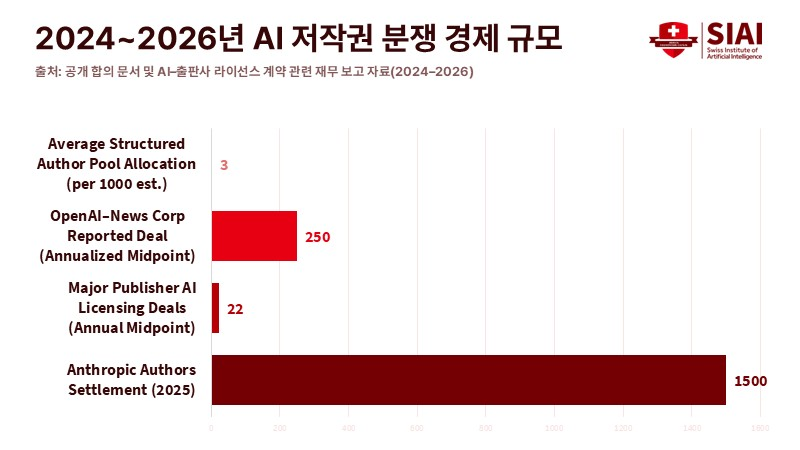
그간 인공지능(AI) 저작권 소송은 저작권법상 ‘공정 이용(Fair use)’의 적용 한계가 핵심 쟁점이었다. 가장 논란이 된 사건은 한 AI 기업이 약 46만5,000권의 도서를 AI 모델 학습에 사용했다는 의혹에서 비롯됐다. 이 사건은 지난해 말 판결 대신 합의로 종결됐고, 법원은 15억 달러(약 2조1,600억원) 규모의 합의안을 승인했다.
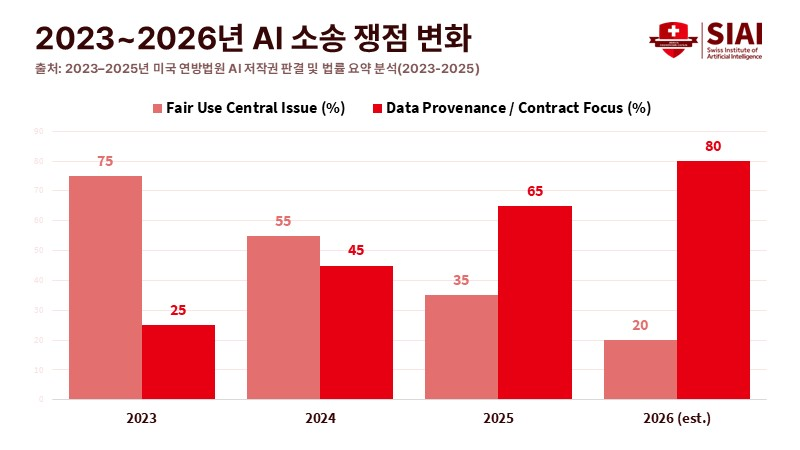
이번 합의는 공정 이용의 경계를 구체적으로 제시하지는 못했다. 다만 데이터 확보 경로와 이용 권한이 불분명할 경우 기업이 부담해야 할 비용이 어느 수준인지 분명히 드러냈다. 이를 계기로 분쟁의 초점도 달라졌다. AI 학습 행위의 위법성 판단을 둘러싼 공방보다, 사용된 데이터의 출처와 계약 관계를 얼마나 명확히 입증할 수 있는지가 쟁점으로 자리 잡았다.
데이터 '출처'가 핵심
공정 이용은 저작권자의 허락 없이도 일정 요건을 충족하면 저작물을 제한적으로 활용할 수 있도록 한 법리다. 이용 목적과 사용 분량, 시장 영향 등을 종합적으로 고려해 판단한다. AI 저작권 논의는 그동안 이 공정 이용의 적용 범위에 집중돼 왔다. 그러나 이러한 법리 중심 접근은 기업이 어떤 관리 기준과 내부 통제 체계를 갖춰야 하는지에 대해서는 충분한 기준을 제시하지 못했다.
2024년 이후 분쟁은 보다 구체적인 사실관계에 초점을 맞추기 시작했다. 학습 데이터의 출처, 적용된 계약 조건, 불법 복제물 포함 여부, 생성 결과와 기존 저작물의 연관성 등이 판단 과정에서 주요 요소로 다뤄졌다. 법리 해석을 넘어 데이터 확보와 관리 실태가 검토 대상에 오른 것이다. 이에 따라 기업의 대응 전략도 변화하고 있다. 데이터 수집 경로를 기록하고 라이선스 범위를 점검하며 내부 통제 체계를 정비하는 일이 리스크 관리의 핵심으로 부각됐다.
계약 중심으로 재편되는 시장
이 같은 변화는 시장에서도 확인된다. AP통신에 따르면 출판사와 언론사 등 콘텐츠 보유 기업들은 장기 소송보다 라이선스 계약을 통한 수익 확보에 무게를 두고 있다. 2025년 중반 이후 주요 출판사와 뉴스 서비스가 AI 개발사와 잇따라 계약을 체결한 배경이다.
AI 기업 역시 데이터 사용 근거를 사전에 확보하는 방식을 선호하는 분위기다. 데이터 접근이 차단될 경우 사업 차질이 불가피하다는 판단에서다. 분쟁의 중심이 학습의 위법성 여부에서 데이터 출처와 계약 범위로 이동하면서, 계약 체결은 위험 관리 수단으로 자리 잡았다. 일부 대형 출판사는 연간 수백만 달러(수십억원)를 받고 콘텐츠 사용을 허용하고 있으며, 특정 계약은 연 2,000만~2,500만 달러(약 288억~360억원) 규모로 알려졌다.
최근 판결에서도 판단의 무게는 구체적 자료에 실렸다. 데이터 확보 경로와 계약 범위가 주요 쟁점으로 다뤄지면서, 관련 기록을 갖춘 기업이 협상 과정에서 유리한 위치를 확보하는 구조가 형성됐다. 정책 측면에서도 시사점이 분명하다. 데이터 제공자와 계약 조건, 수정 이력을 체계적으로 관리할 경우 대규모 합의나 서비스 중단 위험을 낮출 수 있다. AI 시장의 질서가 법리 논쟁보다 계약과 관리 역량에 의해 좌우되는 방향으로 재편되는 양상이다.
교육 현장의 데이터 관리 과제
이러한 흐름은 교육 현장에도 직접적인 영향을 미친다. 강의 자료와 연구 성과, 강의 영상 등 자체 콘텐츠를 생산하는 동시에 외부 데이터를 활용해 AI 시스템을 도입하고 있기 때문이다. 공급자와 이용자의 역할이 동시에 요구되는 구조다.
따라서 학습에 활용되는 데이터의 범위를 명확히 정리하는 작업이 선행돼야 한다. 확보 경로와 적용되는 라이선스 조건, 사용 허용 범위를 문서화하지 않으면 분쟁 발생 시 대응 여지가 좁아진다. 계약서에는 모델 학습 허용 범위와 2차 활용 가능성, 수익 배분 방식 등을 구체적으로 반영할 필요가 있다. 아울러 데이터 가공 과정과 사용 이력을 기록해 외부 점검이 가능하도록 하는 관리 체계도 요구된다.
이 같은 준비는 재무 부담 감소와 직결된다. 교과서 발행사는 AI 기업과의 라이선스 계약을 통해 추가 수익을 확보할 수 있고, 출처가 정리된 데이터로 학습한 모델을 도입한 기관은 법률 비용과 평판 위험을 줄일 수 있다. 정부가 표준화된 기록 체계와 라이선스 중개 인프라를 구축할 경우 비용 부담을 완화하면서 창작자 권리를 보호하는 기반도 마련할 수 있다.
제도적 균형 필요
다만 대규모 합의와 민간 중심의 라이선스 체계가 자금력 있는 기업에 유리하게 작동할 수 있다는 우려도 제기된다. 비용을 감당할 수 있는 기업만 데이터에 접근하게 될 경우 정보 활용 격차가 확대될 가능성이 있다는 지적이다. 반대로 무단 사용이 방치될 경우에도 산업 전반의 신뢰가 훼손되고 서비스 중단과 손해배상 분쟁이 반복될 수 있다. 데이터 확보 기준이 모호한 상태가 지속되면 불확실성은 커질 수밖에 없다.
결국 필요한 것은 균형 잡힌 제도 설계다. 계약을 통한 시장 질서를 인정하되, 반독점 점검과 연구 목적 활용에 대한 명확한 기준, 투명성 확보 장치를 병행해야 한다. 단계적 라이선스 구조와 표준화된 데이터 등록 체계는 과도한 부담을 줄이는 대안으로 거론된다. 비상업적 연구를 위한 공공 라이선스 데이터셋을 조성하는 방안도 검토 대상이다.
AI 저작권 분쟁은 공정 이용 해석을 둘러싼 논쟁을 넘어 데이터 관리 역량을 평가하는 단계로 접어들었다. 학습에 활용된 데이터의 출처와 이용 범위를 설명할 수 있는 체계를 갖춘 주체가 안정성을 확보하는 환경이다. 기준 정립이 지연될 경우 분쟁과 비용 부담은 반복될 공산이 크다.
본 연구 기사의 원문은 Copyright’s Quiet Pivot: Why AI data governance — not fair use — will decide the next phase of legal rulesAct을 참고해 주시기 바랍니다. 본 기사의 저작권은 스위스 인공지능연구소(SIAI)에 있습니다.















