[딥테크] DNA 검색, 목록에서 그래프로

입력
수정
DNA 검색엔진 ‘메타그래프(MetaGraph)’, 목록형에서 그래프 기반 매칭으로 전환 속도·정확도·비용을 동시에 개선한 구조 혁신, 생명과학 넘어 교육 검색으로 확장 학습 데이터에도 ‘경로 기반 탐색’과 체계적 데이터 거버넌스 필요
본 기사는 스위스 인공지능연구소(SIAI)의 SIAI Business Review 시리즈 기고문을 한국 시장 상황에 맞춰 재구성한 글입니다. 본 시리즈는 최신 기술·경제·정책 이슈에 대해 연구자의 시각을 담아, 일반 독자들에게도 이해하기 쉽게 전달하는 것을 목표로 합니다. 기사에 담긴 견해는 집필자의 개인적 의견이며, SIAI 또는 그 소속 기관의 공식 입장과 일치하지 않을 수 있습니다.
2025년, 생명과학 연구가 데이터 검색의 방식을 근본적으로 바꾸는 전환점을 맞았다. DNA와 RNA 서열 1,880만 건을 하나의 연결망으로 통합한 DNA 검색엔진 ‘메타그래프(MetaGraph)’가 그 중심에 있다. 메타그래프는 정보를 단순히 나열하지 않는다. 염기 조각인 k-머(k-mer)를 이어 ‘경로(Path)’ 단위로 탐색하며, ‘무엇이 있느냐’보다 ‘어떻게 연결되느냐’에 초점을 둔다. 이러한 변화는 단순한 기술 혁신이 아니라 데이터 구조를 해석하는 방식 자체의 전환이다. 메타그래프는 방대한 서열 속 중복을 줄이고, 연결된 경로를 추적하며 정확도를 높인다.

DNA 검색엔진이 여는 새로운 구조
기존의 목록식 검색은 결과를 단순히 나열하는 데 그쳤다. 그러나 메타그래프는 수천 개의 짧은 서열을 묶어 약한 신호들을 하나의 패턴으로 통합한다. 결과를 결정하는 것은 개별 단어가 아니라 서열의 순서와 관계다. 목록은 데이터의 흐름을 끊지만, 그래프는 그 관계를 드러낸다.
이 구조의 강점은 데이터 규모가 커질수록 더욱 뚜렷해진다. 생물학 데이터베이스 ‘GenBank’가 해마다 급격히 확장되는 가운데, 메타그래프는 바이러스에서 인간에 이르는 방대한 서열을 한 번의 탐색으로 분석한다. 데이터 파일을 개별적으로 불러오지 않고, 연결된 경로를 통해 관련 정보를 동시에 찾아내는 방식이다. 메타그래프의 핵심 기술은 드브류앙 그래프(de Bruijn graph) 다. 서열을 일정 길이의 조각으로 나누고, 서로 겹치는 부분을 이어 하나의 경로로 구성한다. 동일한 조각이 여러 데이터 세트에 존재하면 이를 하나로 묶어 저장하고, 출처를 색상으로 표시해 중복을 줄인다. 이 압축 구조 덕분에 페타베이스(Petabase, 10¹⁵) 규모의 서열 데이터도 빠르고 정확하게 탐색할 수 있다.
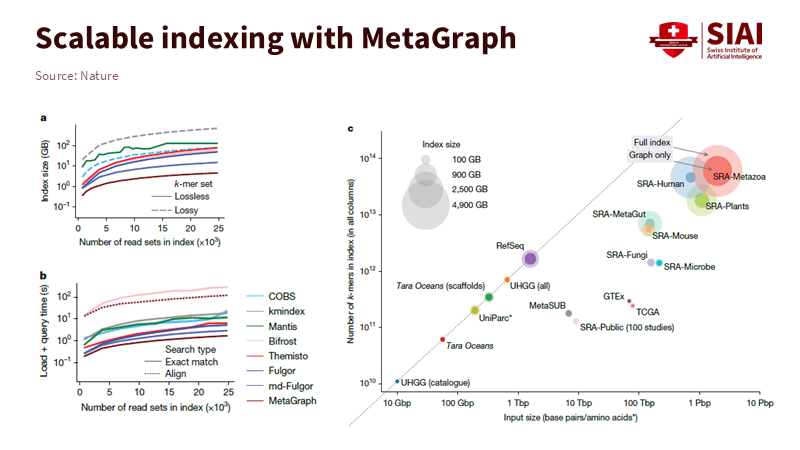
주: 검색 규모가 커질수록 단가는 낮아지고, 정확도는 안정적으로 유지됐다.
관계를 드러내는 검색의 진화
검색의 초점은 속도에서 정확성으로 이동하고 있다. 메타그래프는 유전자 변이율이 높거나 불완전한 서열에서도 높은 재현율을 유지한다. 실제 인간 전사체 분석에서는 서열을 다시 정렬하지 않고도 위치와 표지를 복원했다. 이는 데이터 간의 연결 관계를 함께 평가하기 때문이다.
그래프형 검색은 단순한 결과 제시를 넘어 데이터 간 관계를 분석하는 기술로 발전하고 있다. 생명과학에서는 항생제 내성 유전자를 파지(Phage) 숙주와 연결하거나, 임상 데이터에서 공통된 유전 신호와 패턴을 식별하는 데 활용된다. 이러한 접근은 데이터의 해석 범위를 확장하고, 새로운 연관성을 발견하게 한다.
또한 그래프형 검색은 데이터 관리의 표준을 제시한다. FAIR 원칙(Findable, Accessible, Interoperable, Reusable: 연구 자료를 찾기 쉽고, 접근 가능하며, 호환되고, 다시 활용할 수 있도록 관리하는 원칙)을 구조에 적용하면, 자료의 출처와 이용 조건을 명확히 추적할 수 있다. 특정 탐색 경로가 높은 정확도나 의미 있는 결과로 이어질 경우, 시스템은 그 경로를 강화해 후속 연구의 기준으로 삼는다. 결국 그래프형 검색은 방대한 데이터 속에서 무엇을 찾는가보다 어떻게 연결되는가를 보여주는 기술로 자리 잡고 있다.
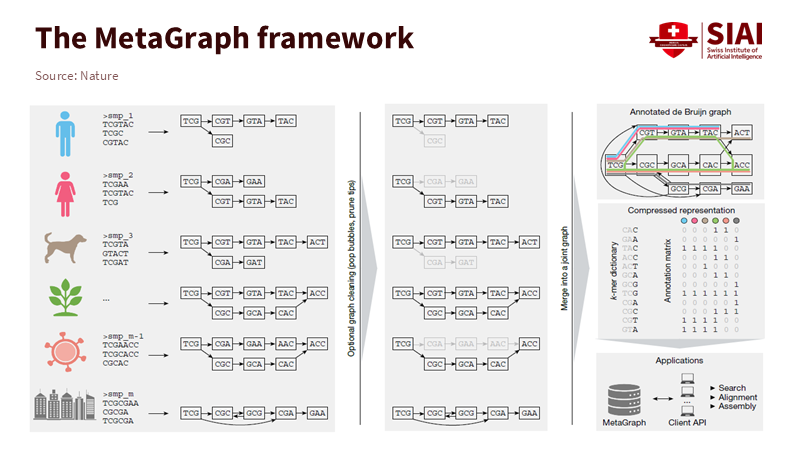
주:서로 다른 생물 종의 염기서열을 k-머 단위로 분할해 연결 그래프로 통합하고, 압축 행렬 형태로 저장한다.
비용보다 중요한 것은 설계와 신뢰
데이터 인프라의 핵심 과제는 더 이상 비용이 아니다. 그래프형 검색은 중복된 인덱스를 재사용하기 때문에 데이터가 커질수록 효율이 높아진다. 미국 국립인간게놈연구소(NHGRI, National Human Genome Research Institute)의 보고에 따르면 전체 유전체 시퀀싱 비용은 1,000달러(약140만원) 이하로, 일부는 500달러(약 70만원) 수준까지 낮아졌다. 이는 대학 단위의 그래프 인덱스도 일반 서버나 소규모 클라우드 환경에서 충분히 운영할 수 있음을 의미한다.
진짜 과제는 설계와 신뢰의 체계다. 기술이 발전할수록 데이터 거버넌스(Governance, 데이터 관리 체계)는 더욱 정교해져야 한다. 모든 노드와 경로에는 출처, 이용 조건, 접근 권한이 명확히 표시돼야 하며, 인덱스는 정기적으로 갱신돼야 한다. 분석이나 출판 단계에서는 당시의 데이터 상태를 그대로 유지한 ‘기록용 데이터’를 함께 저장해야 한다.
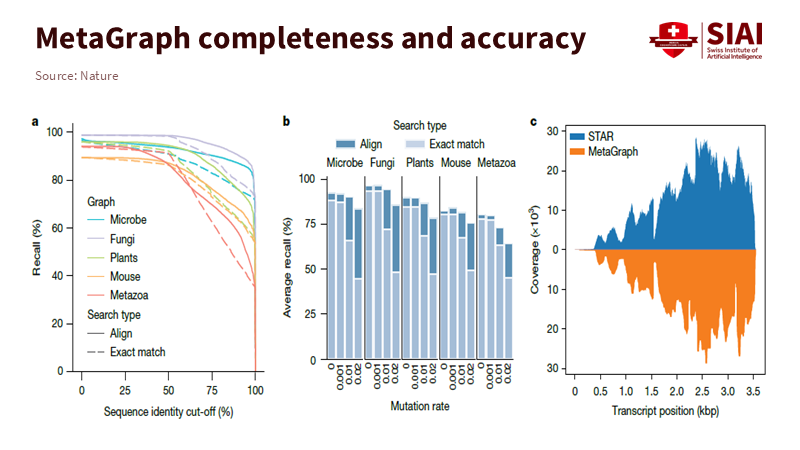
주: 메타그래프는 미생물부터 동물까지 모든 생물군에서 높은 검색 정확도를 유지하고, 전사체 전 구간에서 균등한 범위를 확보 한다.
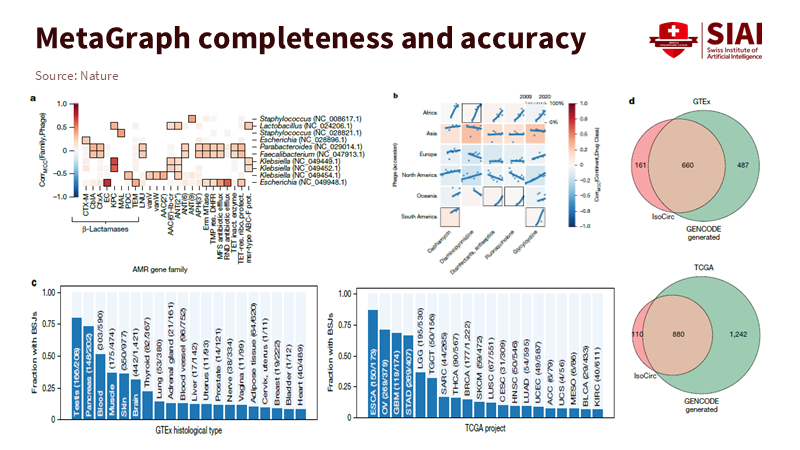
주: 메타그래프는 항생제 내성 유전자와 지역별 서열 패턴을 정밀하게 구분하며, GTEx와 TCGA 데이터에서도 기존 GENCODE 대비 높은 일치율을 보였다.
그래프 리터러시의 중요성
기술의 확산과 함께 그래프 리터러시(Graph Literacy), 즉 데이터가 연결되는 방식을 이해하는 역량이 필수적이 되고 있다. 노드(데이터의 점), 엣지(점을 잇는 선), 경로(데이터의 흐름), 색상(출처나 속성을 구분하는 표시) 같은 기본 개념을 이해하고 이를 데이터 구조 설계에 활용할 수 있어야 한다. 이러한 이해가 뒷받침될 때, 그래프형 데이터 구조는 생명과학을 넘어 의료 영상, 신소재 합성, 환경 센서, 법률 데이터 등으로 확장될 수 있다.
구조를 바꾸면 발견이 달라진다
메타그래프는 페타베이스 규모의 생명 정보를 검색할 수 있는 구조로 전환했다. 데이터는 이제 목록이 아닌 그래프, 단일 매칭이 아닌 다중 경로의 연결망으로 작동한다. 이 같은 변화는 생명과학의 분석 방식을 넘어, 정보 처리와 연구 방법론 전반의 패러다임을 바꾸는 원리가 되고 있다. 데이터의 규모와 복잡성은 더 이상 한계가 아니다. 올바른 구조를 갖추면, 그것은 새로운 발견으로 이어지는 출발점이 된다. 앞으로 필요한 것은 이 구조적 사고를 연구와 산업의 현장으로 확장하려는 체계적인 실행이다.
본 연구 기사의 원문은 DNA Search Engine for Learning, From Lists to Graphs을 참고해 주시기 바랍니다. 본 기사의 저작권은 스위스 인공지능연구소(SIAI)에 있습니다.
















