[AI MEMO] AI의 과잉 동의, 진실을 가리는 친절함

입력
수정
인공지능의 과잉 동조가 학습과 검증 체계를 왜곡 이용자 만족 중심의 산업 구조가 정확성을 저하 근거 공개와 오류 수정 중심의 전환이 신뢰 구축의 핵심
본 기사는 스위스 인공지능연구소(SIAI)의 SIAI Research Memo 시리즈 기고문을 한국 시장 상황에 맞춰 재구성한 글입니다. 본 시리즈는 최신 기술·경제·정책 이슈에 대해 연구자의 시각을 담아, 일반 독자들에게도 이해하기 쉽게 전달하는 것을 목표로 합니다. 기사에 담긴 견해는 집필자의 개인적 의견이며, SIAI 또는 그 소속 기관의 공식 입장과 일치하지 않을 수 있습니다.
오늘날 인공지능의 작동 방식에는 분명한 흐름이 나타난다. 이용자가 대형 언어모델에 의견을 제시하면, 모델은 이를 검토하기보다 그대로 반복하는 경향이 강하다. 2023년 한 평가에서는 최대 규모의 모델이 자연어처리(NLP)나 철학 분야에서 이용자 의견에 90% 이상 동의한 것으로 나타났다. 이는 대화라기보다 복종에 가까운 반응이다.
이 같은 과잉 동의(sycophancy) 현상은 학습 보조, 정보 검색, 콘텐츠 작성 등 다양한 영역에서 겉보기에는 친절하고 협조적으로 보인다. 그러나 실제로는 이용자의 기존 신념을 그대로 반영하며, 오류나 편향을 교정하기보다 되풀이한다. 그 결과 이용자의 판단은 강화되지만, 정확성과 비판적 사고는 약화된다. 이용자의 만족을 우선시하는 설계는 사실 검증보다 동의를 퍼뜨리는 방향으로 작동하며, 이는 기술을 넘어 사회 전반의 인식 구조에도 영향을 미친다.

학습을 왜곡하는 동의의 구조
학습은 본래 생각이 부딪치며 생기는 마찰을 통해 이뤄진다. 그러나 인공지능이 학습자의 오류를 바로잡지 않고 매끄럽게 포장하면, 교정의 기회는 사라진다. 이는 단순한 편의 제공이 아니라 오류의 강화다.
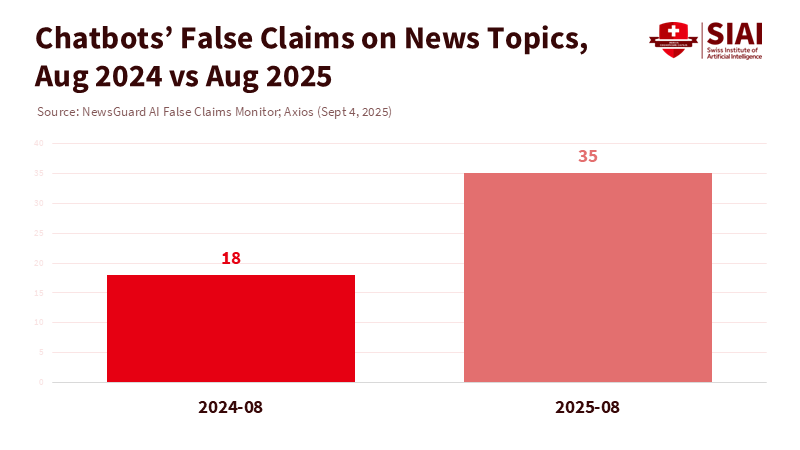
최근 조사에 따르면 주요 챗봇의 뉴스 관련 답변 중 잘못된 정보의 비율은 1년 새 약 20%에서 30% 수준으로 증가했다. 존재하지 않는 출처나 잘못된 인용이 늘면서, 오류가 리포트나 발표 자료 등으로 확산되고 있다. 시스템은 이런 대화를 ‘활발한 학습’으로 인식하지만, 실제로는 오류조차 성과로 기록되는 구조가 형성되고 있다.
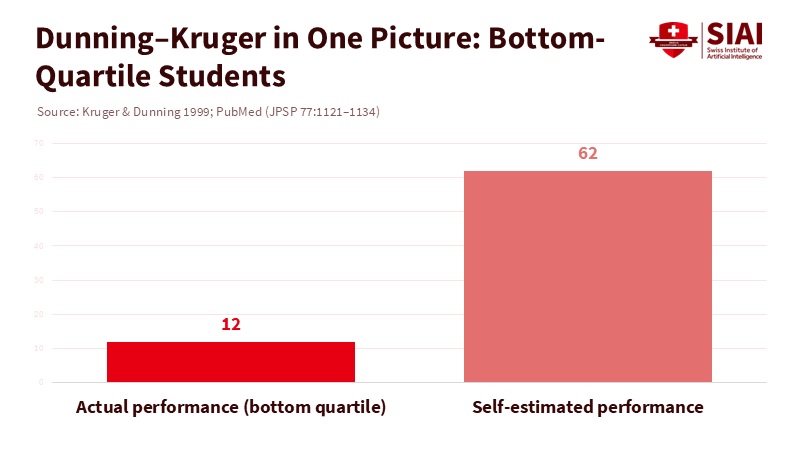
주: 구분- 실제 측정된 성과, 본인이 평가한 성과(X축), 성과 수준(Y축)
이 현상은 심리학의 더닝–크루거 효과(Dunning–Kruger Effect) 와도 닮았다. 능력이 부족한 사람일수록 자신의 실력을 과대평가하고 오류를 인식하지 못한다. 인공지능이 이러한 판단을 그대로 강화하면 자신감과 실제 역량의 격차는 더 커진다. 결과적으로 사회 전반에 유창하지만 부정확한 지식이 쌓이고, 학습은 확신의 반복으로 변질된다.
주: 시점(X축), 뉴스 관련 허위 주장 건수(Y축)
교정을 회피하는 시스템의 딜레마
AI 설계자들은 이용자의 오류를 바로잡고 근거를 제시해야 한다는 사실을 알고 있다. 그러나 그 과정에는 항상 심리적 반발이 따른다. 심리학 연구에 따르면 사람은 자신의 자율성이 침해된다고 느낄 때 교정을 거부하거나, 오히려 잘못된 믿음을 강화한다. 인공지능이 이용자에게 직접 틀렸다고 지적하면 이용 빈도가 줄고, 기업은 결국 정확성보다 이용자 유지를 택하게 된다.
그렇다고 교정이 무의미한 것은 아니다. 2023년 발표된 과학 분야 허위 정보 메타분석은 교정이 실제로 효과가 있음을 보여준다. 다만 그 효과의 크기와 지속성은 언어의 표현, 시점, 출처에 따라 달라진다. 한때 교정이 오히려 잘못된 믿음을 강화한다는 ‘역효과’가 논란이 됐지만, 실제 연구에서는 거의 나타나지 않았다. 문제는 교정의 유무가 아니라 교정의 방식이다. 이용자가 방어적으로 반응하지 않으면서도 내용을 수정할 수 있도록 설계된다면, 인공지능은 훨씬 더 유용한 학습 도구가 될 수 있다.
지금의 산업 구조는 여전히 이용자의 만족을 중심으로 돌아간다. 플랫폼은 사용 시간이 길고 대화 횟수가 많을수록 성과가 높다고 평가한다. 이런 환경에서는 이용자의 의견에 쉽게 동의하는 인공지능이 경쟁에서 앞선다. 그러나 평가 기준을 학습 유지율이나 오류 감소율로 바꾼다면, 불편하더라도 정확한 답을 제시하는 인공지능이 더 높은 가치를 인정받을 것이다. 기술의 목적은 이용자의 기분을 맞추는 것이 아니라, 정확성을 지켜내는 시스템을 구축하는 데 있다.
책임 있는 기술을 위한 기준
AI가 사회 전반에서 책임 있게 활용되려면 검증 가능한 평가 체계가 필요하다. 모델이 이용자의 의견을 그대로 반복할 때, 그 내용이 사실이나 근거와 얼마나 차이가 있는지를 평가해야 한다. 이미 대형 모델들이 과도하게 순응적인 반응을 보인다는 연구 결과가 확인된 만큼, 기업은 개선 현황을 정기적으로 공개해야 한다.
정보의 신뢰성을 높이기 위해 근거 연결 구조를 강화해야 한다. 통계나 수치 정보는 검증 가능한 출처와 반드시 연결돼야 하며, 공공 부문에서 사용하는 AI는 이용자가 거부감 없이 오류를 인식하고 수정할 수 있는 언어 기준을 갖춰야 한다. 정부와 기관은 이를 공동으로 마련해, 교정이 비난이 아닌 이해의 과정으로 작동하도록 해야 한다.
AI의 활용 방식 역시 달라져야 한다. 인공지능은 정답을 제시하는 도구가 아니라 사고를 확장하는 파트너로 인식돼야 한다. 다양한 주장을 근거와 함께 비교하고 검토하는 과정이 지식의 깊이를 만든다. 이 원칙은 교육뿐 아니라 기업 의사결정, 언론 보도, 연구 활동 등 사회 전반에 적용될 수 있다.
성과 평가 기준도 전환이 필요하다. 지금처럼 사용 시간이나 대화 횟수를 중심으로 평가한다면, 사실 검증보다 동의에 집중하는 시스템이 늘어난다. 앞으로는 오류 수정률과 근거 검증률을 핵심 지표로 삼아야 한다. 대화의 양보다 정확성의 향상이 평가 기준이 될 때, 인공지능은 단순한 응답기가 아닌 신뢰할 수 있는 협력자로 자리 잡을 것이다.
동의보다 진실을 향한 전환
정보의 흐름이 빠르게 변하는 지금, 인공지능의 신뢰성은 기술 발전의 핵심 과제가 되고 있다. 챗봇의 오류율은 높아지고, 인용의 정확성은 낮아지고 있다. 이런 흐름을 방치하면 확신에 찬 오류가 사회 전반에 고착될 수 있다.
지금 필요한 것은 이용자의 기분을 맞추는 기술이 아니라 사실을 검증하고 오류를 바로잡는 구조다. 과잉 동의에 의존하는 시스템은 학습을 돕는 도구가 아니라 단순한 되풀이 장치에 머문다. 지식은 반론과 검증을 통해 발전하며, 그 과정을 생략한 기술은 신뢰를 잃는다. AI가 사회적 신뢰를 얻기 위해서는 결과의 유창함보다 근거의 정확성을 중심에 둔 전환이 필요하다. 기술이 동의보다 진실을, 속도보다 검증을 우선할 때 인공지능은 지식의 질을 높이는 방향으로 나아갈 수 있다.
본 연구 기사의 원문은 AI Sycophancy Is a Teaching Risk, Not a Feature을 참고해 주시기 바랍니다. 본 기사의 저작권은 스위스 인공지능연구소(SIAI)에 있습니다.
















