[AI MEMO] 알고리즘 채용이 만든 ‘보이지 않는 탈락’

입력
수정
AI 채용 확대로 평가에서 누락되는 지원자 증가 핵심 정보 부족으로 집단별 차이를 제대로 점검하기 어려운 구조 누락 정보 공개와 사람의 직접 확인이 배제 완화의 핵심 과제
본 기사는 스위스 인공지능연구소(SIAI)의 SIAI Research Memo 시리즈 기고문을 한국 시장 상황에 맞춰 재구성한 글입니다. 본 시리즈는 최신 기술·경제·정책 이슈에 대해 연구자의 시각을 담아, 일반 독자들에게도 이해하기 쉽게 전달하는 것을 목표로 합니다. 기사에 담긴 견해는 집필자의 개인적 의견이며, SIAI 또는 그 소속 기관의 공식 입장과 일치하지 않을 수 있습니다.

2024년 글로벌 HR 조사에 따르면 전체 기업의 절반 이상이 이미 채용 과정에 AI를 활용하고 있다. 그러나 최근 이력서 자동분석 도구에 대한 법정 감사에서는 지원자 평가에 필요한 항목의 11.4%가 시스템에서 처리되지 않아 분석에서 제외된 사실이 확인됐다. 이는 평가에 필요한 정보의 일부가 초기 단계부터 누락되고 있음을 보여준다.
대규모 매칭 플랫폼을 점검한 또 다른 감사에서도 6,000만건이 넘는 지원서에서 인종·출신배경 정보가 확인되지 않았다. 공정성 평가에 필요한 기본적인 집단별 정보가 빠져 있었기 때문에, 어떤 집단이 어떤 결과를 받았는지 비교·검증하기 어려운 구조가 드러난 것이다. 시스템이 필요한 정보를 처리하지 못하는 경우 해당 지원자는 평가 절차에 도달하지 못한 채 제외되며, 이러한 배제는 이미 채용 과정 전반에서 반복적으로 나타나는 구조적 문제로 지적되고 있다.
알고리즘 배제의 구조적 성격
알고리즘 공정성 논의는 대체로 예측 결과의 불균형에 초점을 맞춰 왔다. 그러나 실제 배제는 그보다 앞선 단계에서 시작된다. 모델이 설계 한계나 데이터 부족으로 일부 지원자를 평가 대상으로 인식하지 못하면, 이들은 처음부터 절차에 포함되지 않는다. 이러한 누락이 반복되면 평가 과정 전반에서 구조적 배제가 형성된다. 이렇게 처리되지 않은 기록은 기존 감사 방식에서 포착되지 않는다. 대부분의 감사가 점수가 부여된 지원자만 분석하기 때문이다. 겉으로는 문제가 없는 것처럼 보이지만, 실제로는 상당한 규모의 지원자가 평가 초기 단계에서 누락되고 있는 셈이다.
이 문제는 여러 기술 분야에서 이미 확인되고 있다. 미국 국립표준기술연구소(NIST)는 얼굴인식 기술에서 연령·성별에 따라 오류율이 크게 달라진다는 결과를 반복적으로 발표해 왔고, 음성인식 기술 역시 특정 방언 사용자에게 더 높은 오류율을 보인다는 연구가 이어지고 있다. 채용 분야에서도 뉴욕시 등 일부 지역이 자동화 도구에 대한 편향 감사를 의무화하고 있지만, 많은 감사가 여전히 ‘정보 없음’으로 표시된 기록을 분석에서 제외한다. 이러한 관행은 영향 여부를 확인해야 할 집단이 검증 과정에 포함되지 못하는 문제를 고착시킨다.
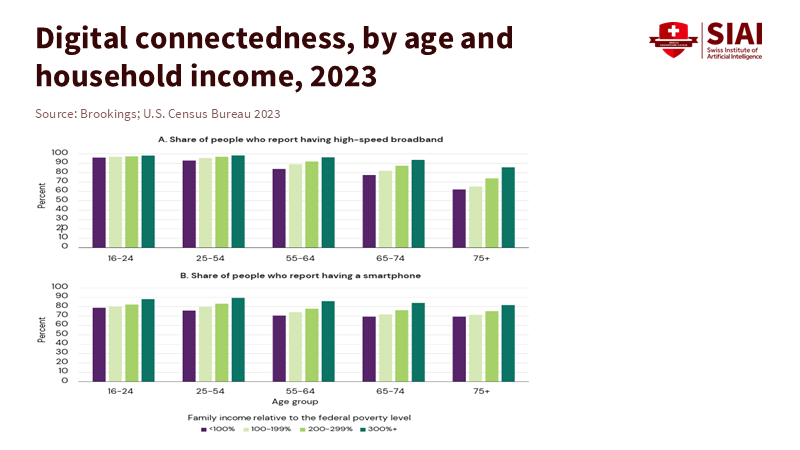
주: 고령층과 저소득층의 광대역·스마트폰 이용률이 낮아지면서, AI 기반 채용·교육 환경에서 ‘비접속’이 곧 ‘배제’로 이어질 가능성이 커지고 있다.
채용에서 나타나는 배제의 확대
2024년 1~8월 이력서 스크리닝 감사 결과는 배제 규모를 구체적으로 보여준다. 총 12만3,610개 평가 기준을 분석한 결과, 법적 판단 기준인 5분의 4 법칙(four-fifths rule, 특정 집단의 선발률이 다른 집단의 80% 미만이면 차별 가능성이 있다고 보는 기준)에는 저촉되지 않았다. 그러나 전체 기준의 11.4%는 시스템에서 처리되지 않아 공정성 분석에 포함되지 않았다.
처리된 데이터에서도 집단 간 차이는 확인됐다. 백인 지원자의 기준 충족률은 71.5%, 아시아인 지원자는 64.4%였으며, 아시아계 여성 역시 중간 수준의 영향비율을 보였다. 이러한 편차는 평가 과정에서 집단별 결과가 동일하게 나타나지 않는다는 점을 보여준다. 특히 경력 단절이나 비연속적 학력을 가진 지원자에게 처리 불가 항목이 집중될 경우, 이들은 평가 단계에 도달하기도 전에 자동으로 배제되는 구조가 형성될 수 있다.
데이터 규모가 커질수록 문제는 더욱 뚜렷하게 나타난다. 2025년 한 대형 매칭 플랫폼 감사에서는 성별 정보는 약 2,000만건에서 확인됐지만, 인종·출신배경 정보는 6,026만건에서 확인되지 않은 것으로 나타났다. 이는 공정성 검증을 위해 반드시 필요한 기초 자료가 대규모로 누락된 상황이었으며, 이런 환경에서는 집단별 차이나 영향 여부를 평가하는 절차 자체가 작동하기 어렵다.
AI 채용 도구의 활용이 빠르게 확대되는 점을 고려하면 이러한 결함은 더욱 큰 영향을 미친다. 2024년 기준 전체 기업의 절반 이상이 채용 과정에 AI를 도입했고, 45%는 이력서 필터링에 직접 사용하고 있다. 자동화 초기 단계에서의 오류나 정보 누락은 많은 지원자가 사람의 검토를 받기도 전에 탈락하는 결과로 이어질 수 있다.
규제기관도 대응을 강화하고 있다. 미국 고용평등위원회(EEOC)는 자동화 도구 사용 시에도 민권법 제7편(Title VII, 고용에서 차별을 금지하는 법)이 동일하게 적용된다고 명확히 밝혔다. 미 연방 계약규정국(OFCCP)은 연방 계약자에게 AI 기반 선발 절차의 타당성을 검증하도록 요구하고 있으며, 뉴욕시의 자동화 고용결정도구에 대한 감사 법(Local Law 144) 역시 기업의 책임을 강화하고 있다. 그럼에도 불구하고 감사 과정에서 정보 누락 항목이 배제된다면 실제 배제 규모는 여전히 드러나지 않는다.
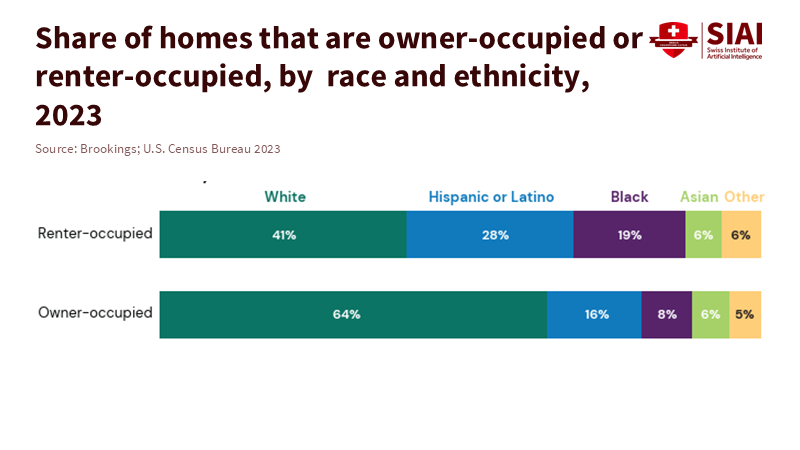
주: 흑인과 히스패닉 가구의 임차 비중이 높다는 점은 주소 변동이 잦고 행정 기록이 불완전할 가능성을 보여준다. 이러한 조건은 필수 정보가 누락된 신청서를 증가시켜, 알고리즘 기반 시스템에서 배제 위험을 높일 수 있다.
알고리즘 배제를 줄이기 위한 기준
배제를 줄이기 위해서는 먼저 시스템이 처리하지 못한 기록의 규모를 정확히 확인하는 절차가 필요하다. 미결정이나 처리 불가, 채점 누락이 얼마나 발생했는지를 집단별로 공개하고, 이를 경력 단절, 학력 변경, 저속 인터넷 환경 등 지원자의 조건과 함께 분석해야 한다. 특정 집단에서 처리 실패가 반복된다면 자동화 대신 사람이 검토하는 절차가 뒷받침돼야 한다.
또한 동일한 목적을 유지하면서 배제를 줄일 수 있는 절차를 우선적으로 채택해야 한다. 경계에 걸린 경력이나 학업 이력은 자동 탈락이 아니라 사람이 확인하는 방식으로 전환하고, 기술 기반 질문이나 표준화된 과제를 활용해 평가의 기초 자료를 확충해야 한다. 모호한 대체 변수를 사용하는 대신 구조화된 데이터를 확보하면 더 많은 지원자가 평가 과정에 진입할 수 있다.
마지막으로 소프트웨어 결함을 줄이는 관리가 필수적이다. 실제 배제의 상당 부분은 알고리즘 자체보다는 데이터 처리 과정의 오류나 설정 문제에서 발생한다. 2022년 미국의 소프트웨어 품질 결함 비용은 2조41억달러(약 3,545조원)로 추산된다. 이러한 규모를 감안하면 배포 전 점검은 알고리즘뿐 아니라 데이터 흐름과 의사결정 절차 전체를 대상으로 해야 하며, 처리 실패 기록은 반드시 남겨야 한다. 업데이트 후 배제 비율이 증가할 경우 즉시 수정하거나 이전 상태로 되돌릴 필요가 있다.
채점에서 누락되는 사람들
AI 거버넌스에서 가장 먼저 확인해야 할 지표는 합격이나 불합격이 아니라 시스템이 처리하지 못한 사람들의 규모다. 최근 감사 결과는 데이터 누락과 처리 실패로 인해 많은 지원자가 평가 단계에 도달하지 못하는 사례가 지속되고 있음을 보여준다.
채점에서 누락된 지원자는 평가 기회를 얻지 못하며, 이는 제도 전반에 대한 신뢰를 약화시킨다. 따라서 알고리즘 배제를 명확한 위험 요소로 다루고, 자동화 과정에서 허용할 수 있는 배제 비율을 미리 정하며, 이를 줄이기 위한 절차를 우선적으로 적용하는 것이 필요하다. 지금 필요한 조치는 명확하다. 누락된 기록을 남기고, 사람이 개입해야 할 지점을 분명히 하며, 데이터를 투명하게 공개해 어느 지원자도 평가 과정 밖에 머물지 않도록 해야 한다.
본 연구 기사의 원문은 When Algorithms Say Nothing: Fixing Silent Failures in Hiring and Education을 참고해 주시기 바랍니다. 본 기사의 저작권은 스위스 인공지능연구소(SIAI)에 있습니다.
















