[딥폴리시] 보험사간 데이터 공유 확대, 보험료 인하 vs 위험 평가 경쟁 약화 논란
[딥폴리시] 보험사간 데이터 공유 확대, 보험료 인하 vs 위험 평가 경쟁 약화 논란

입력
수정
美 보험시장 과점 속 데이터 공유 논쟁 재점화 효율 개선 이면 저위험 수혜·고위험 부담 확대 혁신 유인 유지와 보험 접근성 균형 설계 필요
본 연구 기사는 유럽 경제 연구소 The Economy의 연구위원(Fellow)들이 작성한 The Economy Review 시리즈 기고문을 한국 시장 상황에 맞춰 재구성한 글입니다. 본 시리즈는 최신 기술-경제-정책 이슈에 대해 연구자의 시각을 담아, 일반 독자들에게도 이해하기 쉽게 전달하는 것을 목표로 합니다. 기사에 담긴 견해는 집필자의 개인적인 의견이며, The Economy 또는 집필자의 소속 기관의 견해와 일치하지 않을 수 있습니다.

지난해 기준 미국 개인용 자동차보험 시장은 상위 4개 보험사가 전체 보험료의 57.4%를 차지했다. 이 같은 구조는 자동차보험 데이터 공유를 바라보는 기존 인식을 재검토할 필요성을 제기한다. 그동안 논의는 소수 보험사에 시장이 집중된 구조를 전제로, 대형 보험사가 축적한 위험 정보를 소형 보험사와 공유해 격차를 완화해야 한다는 방향에 머물렀다.
그러나 데이터 공유를 의무화하는 조치는 단순한 정보 공개에 그치지 않는다. 시장의 혁신 구조 전반에 영향을 미칠 수 있기 때문이다. 이미 일부 기업에 집중된 시장에서 정보까지 동일하게 제공될 경우, 더 정교한 위험 모형을 개발하려는 유인이 약해질 수 있다. 또한 투자 없이 시장에 참여한 기업으로 이익이 이전되면서 혁신 성과는 줄어들고, 고위험군을 지탱해 온 비용 분담 구조 역시 약화될 가능성이 크다. 데이터 공유는 공정성의 문제가 아니다. 경쟁 구조와 보험 접근성을 어떻게 설계할지에 관한 정책 선택의 영역이다.
데이터 공유, 효율 개선과 분배 충격
이탈리아 사례는 데이터 공유가 시장 효율을 높인다는 점을 시사한다. 2013~2021년 자동차 책임보험을 분석한 연구에 따르면, 보험사 간 위험 정보 격차가 사라진 환경에서 소비자 잉여는 평균 15.7% 늘고 보험료는 21.6% 낮아졌다. 정보 공유가 가격 경쟁을 강화하고 시장 수요 확대를 이끌었음을 보여주는 대목이다.
그러나 효과는 모든 집단에 동일하게 나타나지 않는다. 같은 분석에서 저위험 운전자의 소비자 잉여는 78.3% 증가한 반면, 고위험 운전자는 33.4% 감소했다. 이는 데이터 공유가 효율을 높이는 동시에 분배 구조에는 다른 영향을 미친다는 점을 드러낸다. 위험 정보가 널리 공유될수록 각 운전자의 위험이 가격에 정확히 반영되고, 그 과정에서 저위험군이 일부 부담해 온 비용 분담 구조는 약해진다. 결과적으로 시장은 정교해지지만, 고위험군의 부담은 더 직접적으로 나타난다.
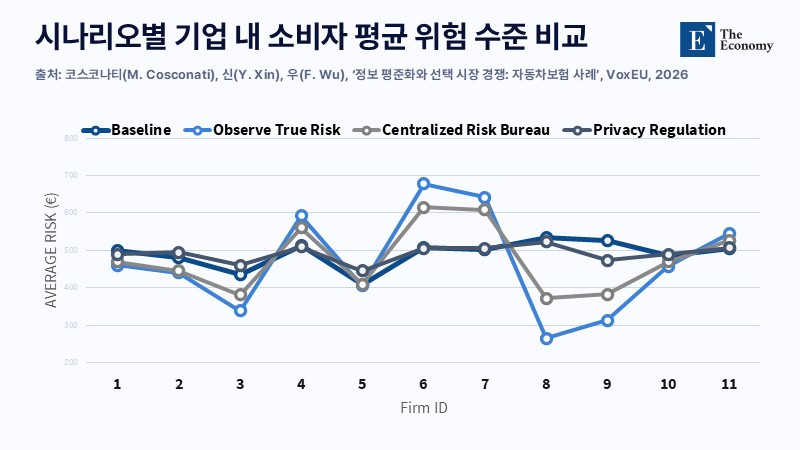
정보 생산 유인과 혁신의 지속성
데이터 공유는 비용 분담 구조뿐 아니라 정보 생산 유인에도 영향을 미친다. 보험사들은 사고 데이터 축적과 텔레매틱스, 사기 탐지 기술에 지속적으로 투자해 왔다. 위험을 정교하게 평가하는 능력이 핵심 경쟁력으로 자리 잡으면서, 미국 보험사의 88%가 인공지능(AI)과 머신러닝 도입을 검토하거나 활용 중이다.
이탈리아의 텔레매틱스 사례가 이를 방증한다. 블랙박스를 장착한 차량은 사고 발생 확률이 15% 낮아졌고, 순보험료도 평균 20% 줄었다. 이는 실제 위험을 낮추는 기술 투자 성과다.
문제는 이 성과가 그대로 공유될 때 발생한다. 기술 투자로 축적된 위험 정보까지 시장 전반에 확산되면, 선행 투자에 대한 보상은 약해질 수밖에 없다. 단기적으로는 보험료 인하 효과가 나타나겠지만, 장기적으로는 데이터 축적과 기술 개발 속도가 둔화될 가능성이 있다. 결국 데이터 공유는 효율을 높이면서도 혁신 유인을 동시에 약화시킬 수 있다는 점을 보여주는 사례다.
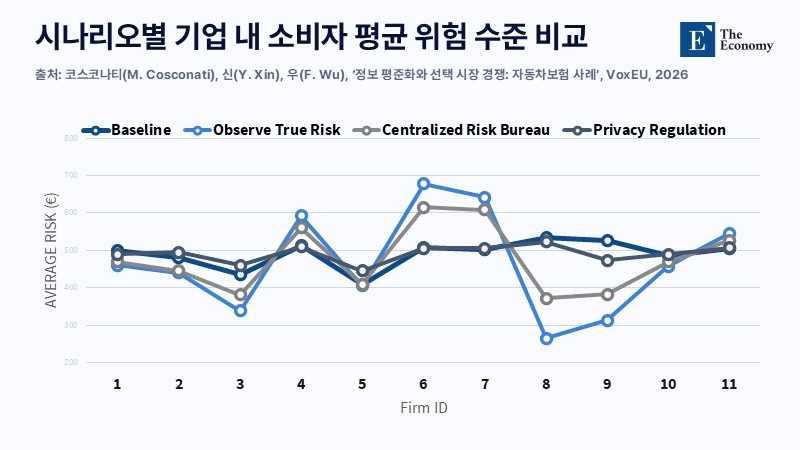
보험의 본질, 예측과 분산의 충돌
보험은 위험을 여러 가입자에게 나눠 부담시키는 구조로 작동한다. 그러나 정보가 널리 공유돼 개인별 위험에 맞춰 가격이 책정되면, 이러한 분산 기능은 약해질 수밖에 없다. 효율성 측면에서는 타당한 변화지만, 그만큼 부담은 개인에게 직접 전가된다. 위험 수준이 가격에 그대로 반영될수록 고위험군은 보험료 상승 압박을 받게 되고, 실제로는 가입이 어려워지는 상황으로 이어질 수 있다.
이 같은 구조 변화는 데이터 공유 정책 설계와 맞물린다. 모든 정보를 동일하게 만드는 방식은 시장의 분산 기능을 훼손할 수 있다. 따라서 데이터 공유는 정보 이동성과 기업 간 모델 경쟁을 구분하는 방향으로 설계돼야 한다. 운전자가 자신의 사고 이력과 운전 기록을 이전할 권리는 보장하되, 이를 해석하고 위험을 평가하는 과정에서는 기업 간 경쟁이 필요하다.
경쟁력과 회복력, 시장 설계의 균형
이러한 정책적 균형 모색은 이미 유럽에서 구체화되는 추세다. 유럽연합(EU)은 지난해 자동차 정책을 통해 차량 운행 데이터 접근 확대와 공용 데이터 플랫폼 구축을 검토했다. 다만 정보 공유 확대에 따른 부작용을 줄이기 위한 장치도 병행돼야 한다. 새로운 정보를 생산한 기업에는 일정 기간 보호나 보상을 제공해 혁신 유인을 유지할 필요가 있다. 동시에 정보 고도화 과정에서 부담이 커질 수 있는 고위험 운전자에 대해서는 보조금이나 비용 분담 장치 등 보완책이 마련돼야 한다.
데이터가 많을수록 시장이 개선된다는 가설은 보험 시장에서는 그대로 적용되기 어렵다. 데이터 공유는 지식 생산에 대한 보상 구조와 위험 부담의 배분 방식을 함께 바꾸는 정책 수단이기 때문이다. 따라서 정책 설계는 단순한 가격 경쟁을 넘어, 시장의 지속 가능한 경쟁력과 사회적 회복력을 함께 확보하는 방향이 요구된다.
본 연구 기사의 원문은 The Hidden Subsidy Inside Auto Insurance Data Sharing을 참고해 주시기 바랍니다. 본 기사의 저작권은 The Economy에 있습니다.
















