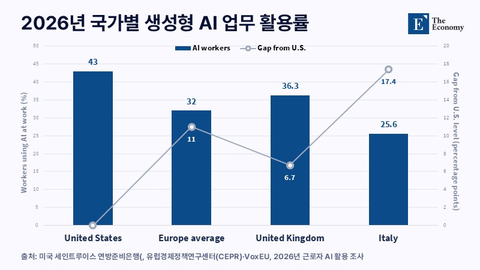
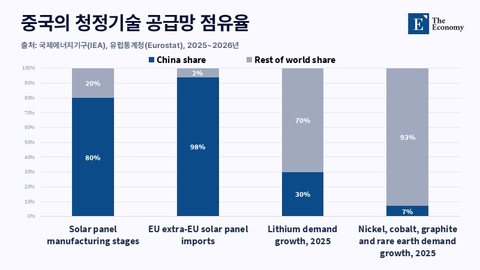
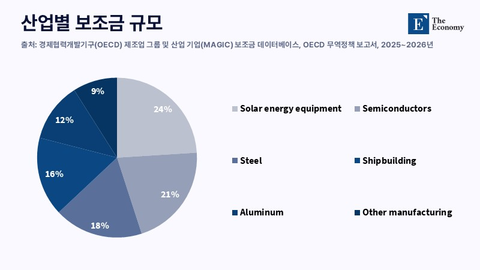
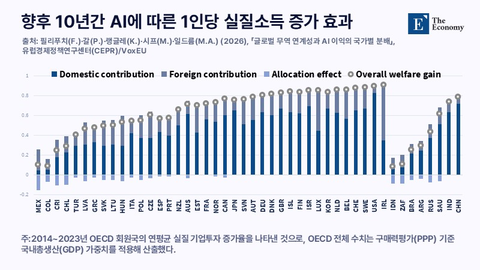
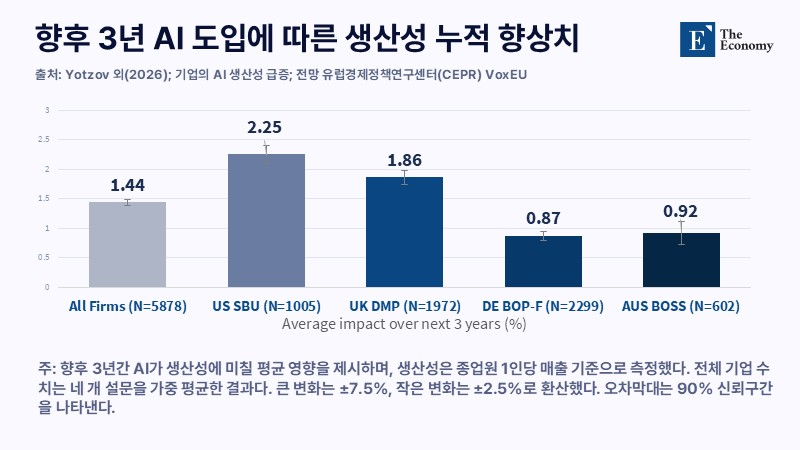
향후 3년 AI 도입에 따른 생산성 누적 향상치
향후 3년 AI 도입에 따른 생산성 누적 향상치
Picture

Real name
The Economy Graphics (Korea)
Bio
더 이코노미 그래픽스(The Economy Graphics)는 The Economy의 시각 자료 제작을 전담하는 데이터 기반 비주얼 리서치 계정입니다. 글로벌 경제, 금융시장, 기술 산업, 정책 변화, 헬스케어, 문화 산업 등 다양한 분야의 핵심 데이터를 차트, 인포그래픽, 분석 그래픽, 시각 요약 자료로 재구성합니다. 연구 논문, 공공 데이터, 국제기구 보고서, 산업 리포트, The Economy 자체 리서치 자료를 바탕으로 복잡한 정보를 명확하고 구조화된 이미지로 전달하는 것이 목표입니다. 단순한 디자인 작업을 넘어 데이터의 흐름, 산업 간 비교, 정책 효과, 시장 구조, 장기 트렌드를 한눈에 이해할 수 있도록 시각화합니다. 더 이코노미 그래픽스는 The Economy Korea의 기사와 리서치 콘텐츠를 보완하며, 독자들이 경제와 산업 변화를 보다 직관적으로 이해할 수 있도록 고품질 그래픽 자료를 제공합니다.
입력
수정
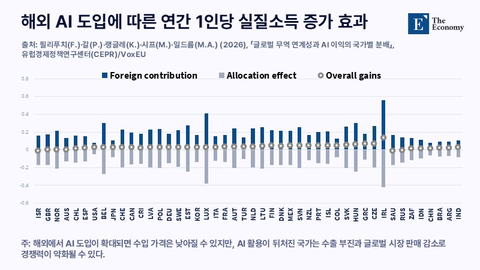
관련 기사: [AI MEMO] AI발 고용 충격, 차이나 쇼크와는 다른 양상 | The Economy Korea
Picture
Real name
The Economy Graphics (Korea)
Bio
더 이코노미 그래픽스(The Economy Graphics)는 The Economy의 시각 자료 제작을 전담하는 데이터 기반 비주얼 리서치 계정입니다. 글로벌 경제, 금융시장, 기술 산업, 정책 변화, 헬스케어, 문화 산업 등 다양한 분야의 핵심 데이터를 차트, 인포그래픽, 분석 그래픽, 시각 요약 자료로 재구성합니다. 연구 논문, 공공 데이터, 국제기구 보고서, 산업 리포트, The Economy 자체 리서치 자료를 바탕으로 복잡한 정보를 명확하고 구조화된 이미지로 전달하는 것이 목표입니다. 단순한 디자인 작업을 넘어 데이터의 흐름, 산업 간 비교, 정책 효과, 시장 구조, 장기 트렌드를 한눈에 이해할 수 있도록 시각화합니다. 더 이코노미 그래픽스는 The Economy Korea의 기사와 리서치 콘텐츠를 보완하며, 독자들이 경제와 산업 변화를 보다 직관적으로 이해할 수 있도록 고품질 그래픽 자료를 제공합니다.